mirror of
https://github.com/sourcegraph/sourcegraph.git
synced 2026-02-06 13:11:49 +00:00
Backport dev docs changes that happened in docsite v2 (#61931)
* backport https://github.com/sourcegraph/docs/pull/216
* backport d1e81d254d
* backprot https://github.com/sourcegraph/docs/pull/158
* backport https://github.com/sourcegraph/docs/pull/135
* backport https://github.com/sourcegraph/docs/pull/150
* backport https://github.com/sourcegraph/docs/pull/138
* backport https://github.com/sourcegraph/docs/pull/115
* backport https://github.com/sourcegraph/docs/pull/123
* backport https://github.com/sourcegraph/docs/pull/118
* fix outgoing links
* backport https://github.com/sourcegraph/docs/pull/51
* backport https://github.com/sourcegraph/docs/pull/26
* backport https://github.com/sourcegraph/docs/pull/23
* Fix broken links
This commit is contained in:
parent
c496f13e3f
commit
85438e62d5
@ -282,3 +282,4 @@ If you want to learn more about observability:
|
||||
## Other resources
|
||||
|
||||
- [Life of a ping](life-of-a-ping.md)
|
||||
- [Row level security (discontinued)](row_level_security.md)
|
||||
|
||||
@ -0,0 +1,173 @@
|
||||
# Row-level security
|
||||
|
||||
> NOTE: this document is deprecated, but preserved for historical and informational purposes.
|
||||
|
||||
Starting with version 9.5, Postgres provides a [row-level security](https://www.postgresql.org/docs/13/ddl-rowsecurity.html) mechanism (abbreviated as "RLS") that can restrict table access in a granular, per-user fashion. Sourcegraph uses this mechanism to provide data isolation and protection guarantees beyond those supplied by application-level techniques. This document serves as a brief overview of the concept, its application at Sourcegraph and administrative implications.
|
||||
|
||||
## Basics of RLS
|
||||
|
||||
Row-level security is enabled for a given table using the `ALTER TABLE <name> ENABLE ROW LEVEL SECURITY` statement. Once executed, all rows within that table immediately become inaccessible to all users _except_ for the table owner or superuser roles who have the `BYPASSRLS` attribute set. Access must then be explicitly permitted by the creation of one or more security policies which are then applied to the table.
|
||||
|
||||
Sourcegraph currently uses a single row security policy, which is applied to the `repo` table and covers all commands (`INSERT`, `SELECT`, etc.)
|
||||
|
||||
```
|
||||
# select tablename, policyname, roles, cmd, format('%s...', left(qual, 16)) as policy from pg_policies;
|
||||
┌───────────┬───────────────────────┬──────────────┬─────┬─────────────────────┐
|
||||
│ tablename │ policyname │ roles │ cmd │ policy │
|
||||
╞═══════════╪═══════════════════════╪══════════════╪═════╪═════════════════════╡
|
||||
│ repo │ sg_repo_access_policy │ {sg_service} │ ALL │ (((NOT (current_... │
|
||||
└───────────┴───────────────────────┴──────────────┴─────┴─────────────────────┘
|
||||
(1 row)
|
||||
|
||||
Time: 0.657 ms
|
||||
```
|
||||
|
||||
## Reducing privileges
|
||||
|
||||
It's not feasible to create a Postgres role for each individual Sourcegraph user. Instead, a dedicated `sg_service` role has been introduced that services can assume to downgrade their own capabilities on demand.
|
||||
|
||||
```
|
||||
# select rolname, rolcanlogin, rolbypassrls from pg_roles where rolname like 'sg_%';
|
||||
┌────────────┬─────────────┬──────────────┐
|
||||
│ rolname │ rolcanlogin │ rolbypassrls │
|
||||
╞════════════╪═════════════╪══════════════╡
|
||||
│ sg_service │ f │ f │
|
||||
└────────────┴─────────────┴──────────────┘
|
||||
(1 row)
|
||||
|
||||
Time: 24.462 ms
|
||||
```
|
||||
|
||||
The `sg_service` role is not associated with any particular application-level Sourcegraph user, nor is it a user capable of logging in by itself. The policy applied to the `repo` table requires several `rls` values to be set, and these values dynamically alter how each query will behave.
|
||||
|
||||
For example, the default `sourcegraph` role in this sample database is permitted to see all 552 rows in the `repo` table because it's the owner of the table.
|
||||
|
||||
```
|
||||
# select current_user;
|
||||
┌──────────────┐
|
||||
│ current_user │
|
||||
╞══════════════╡
|
||||
│ sourcegraph │
|
||||
└──────────────┘
|
||||
(1 row)
|
||||
|
||||
Time: 0.197 ms
|
||||
|
||||
# select count(1) from repo;
|
||||
┌───────┐
|
||||
│ count │
|
||||
╞═══════╡
|
||||
│ 552 │
|
||||
└───────┘
|
||||
(1 row)
|
||||
|
||||
Time: 15.781 ms
|
||||
```
|
||||
|
||||
Once the `sg_service` role is assumed, Postgres needs additional information about which Sourcegraph user is executing the query. In this case, user 42 does not have permission to see the repositories owned by user 1 and no rows are returned. Note that we are executing the same query as before, but receiving different results.
|
||||
|
||||
```
|
||||
# set role sg_service;
|
||||
SET
|
||||
Time: 1.187 ms
|
||||
|
||||
# set rls.user_id = 42;
|
||||
SET
|
||||
Time: 1.206 ms
|
||||
|
||||
# set rls.permission = 'read';
|
||||
SET
|
||||
Time: 0.333 ms
|
||||
|
||||
# set rls.use_permissions_user_mapping = true;
|
||||
SET
|
||||
Time: 0.327 ms
|
||||
|
||||
# select current_user;
|
||||
┌──────────────┐
|
||||
│ current_user │
|
||||
╞══════════════╡
|
||||
│ sg_service │
|
||||
└──────────────┘
|
||||
(1 row)
|
||||
|
||||
Time: 0.381 ms
|
||||
|
||||
# select count(1) from repo;
|
||||
┌───────┐
|
||||
│ count │
|
||||
╞═══════╡
|
||||
│ 0 │
|
||||
└───────┘
|
||||
(1 row)
|
||||
|
||||
Time: 28.288 ms
|
||||
```
|
||||
|
||||
## Bypassing RLS
|
||||
|
||||
Row-level security can be bypassed by setting the `BYPASSRLS` attribute on a role. For example, if we were to create a `poweruser` role without this attribute, the existing security policy would prevent access to the `repo` table by default.
|
||||
|
||||
```
|
||||
# create role poweruser;
|
||||
CREATE ROLE
|
||||
Time: 7.015 ms
|
||||
|
||||
# set role poweruser;
|
||||
SET
|
||||
Time: 0.349 ms
|
||||
|
||||
# select count(1) from repo;
|
||||
┌───────┐
|
||||
│ count │
|
||||
╞═══════╡
|
||||
│ 0 │
|
||||
└───────┘
|
||||
(1 row)
|
||||
|
||||
Time: 21.373 ms
|
||||
```
|
||||
|
||||
We can alter this role to set the `BYPASSRLS` attribute, at which point the security policy will be skipped and the role will have the normal level of access it would expect.
|
||||
|
||||
```
|
||||
# alter role poweruser bypassrls;
|
||||
ALTER ROLE
|
||||
Time: 0.852 ms
|
||||
|
||||
# set role poweruser;
|
||||
SET
|
||||
Time: 0.229 ms
|
||||
|
||||
# select count(1) from repo;
|
||||
┌───────┐
|
||||
│ count │
|
||||
╞═══════╡
|
||||
│ 552 │
|
||||
└───────┘
|
||||
(1 row)
|
||||
|
||||
Time: 6.280 ms
|
||||
```
|
||||
|
||||
Additionally, it is possible to bypass RLS by supplying a policy that explicitly allows a particular role to access the table.
|
||||
|
||||
```
|
||||
# create policy sg_poweruser_access_policy on repo for all to poweruser using (true);
|
||||
CREATE POLICY
|
||||
Time: 8.525 ms
|
||||
|
||||
# set role poweruser;
|
||||
SET
|
||||
Time: 0.338 ms
|
||||
|
||||
# select count(1) from repo;
|
||||
┌───────┐
|
||||
│ count │
|
||||
╞═══════╡
|
||||
│ 552 │
|
||||
└───────┘
|
||||
(1 row)
|
||||
|
||||
Time: 5.782 ms
|
||||
```
|
||||
@ -1,52 +1,52 @@
|
||||
# Building container images with Bazel
|
||||
|
||||
Building containers with Bazel, and using Wolfi for the base images is faster, more reliable and provides much better caching capabilities. This allows us to build the containers in PRs pipelines, not only on the `main` branch.
|
||||
You'll find a lot of mentions of [OCI](https://opencontainers.org/) throughout this document, which refers to the standard for container formats and runtime.
|
||||
Building containers with Bazel, and using Wolfi for the base images is faster, more reliable and provides much better caching capabilities. This allows us to build the containers in PRs pipelines, not only on the `main` branch.
|
||||
You'll find a lot of mentions of [OCI](https://opencontainers.org/) throughout this document, which refers to the standard for container formats and runtime.
|
||||
|
||||
We use [`rules_oci`](https://github.com/bazel-contrib/rules_oci) and [Wolfi](https://github.com/wolfi-dev) to produce the container images.
|
||||
We use [`rules_oci`](https://github.com/bazel-contrib/rules_oci) and [Wolfi](https://github.com/wolfi-dev) to produce the container images.
|
||||
|
||||
See [Bazel at Sourcegraph](./index.md) for general bazel info/setup.
|
||||
See [Bazel at Sourcegraph](./index) for general bazel info/setup.
|
||||
|
||||
## Why using Bazel to build containers
|
||||
## Why using Bazel to build containers
|
||||
|
||||
Bazel being a build system, it's not just for compiling code, it can produce tarballs and all artefacts that we ship to
|
||||
Bazel being a build system, it's not just for compiling code, it can produce tarballs and all artefacts that we ship to
|
||||
customers. Our initial approach when we migrated to Bazel was to keep the existing Dockerfiles, and simply use the Bazel
|
||||
produced binaries instead of the old ones.
|
||||
produced binaries instead of the old ones.
|
||||
|
||||
This sped up the CI significantly, but because Bazel is not aware of the image building process, every build on the `main` branch was recreating the Docker images, which is a time consuming process. In particular, the server image has been the slowest of them all, as it required to build all other service and to package them into a very large image that also contained all the third parties necessary to run them (such as `git`, `p4`, `universal-ctags`).
|
||||
This sped up the CI significantly, but because Bazel is not aware of the image building process, every build on the `main` branch was recreating the Docker images, which is a time consuming process. In particular, the server image has been the slowest of them all, as it required to build all other service and to package them into a very large image that also contained all the third parties necessary to run them (such as `git`, `p4`, `universal-ctags`).
|
||||
|
||||
All of these additional steps can fail, due to transient network issues, or a a particular URL becoming unavailable. By switching to Bazel to produce the container images, we are leveraging its reproduceability and cacheability in exactly the same way we do for building binaries.
|
||||
All of these additional steps can fail, due to transient network issues, or a a particular URL becoming unavailable. By switching to Bazel to produce the container images, we are leveraging its reproduceability and cacheability in exactly the same way we do for building binaries.
|
||||
|
||||
This results in more reliable and faster builds, fast enough that we can afford to build those images in PRs as Bazel will cache the result, meaning we don't rebuild them unless we have to, in a deterministic fashion.
|
||||
This results in more reliable and faster builds, fast enough that we can afford to build those images in PRs as Bazel will cache the result, meaning we don't rebuild them unless we have to, in a deterministic fashion.
|
||||
|
||||
## Anatomy of a Bazel built containers
|
||||
|
||||
Containers are composed of multiple layers (conceptually, not talking about container layers):
|
||||
Containers are composed of multiple layers (conceptually, not talking about container layers):
|
||||
|
||||
- Sourcegraph Base Image
|
||||
- Sourcegraph Base Image
|
||||
- Distroless base, powered by Wolfi
|
||||
- Packages common to all services.
|
||||
- Packages common to all services.
|
||||
- Per Service Base Image
|
||||
- Packages specific to a given service
|
||||
- Service specific outputs (`pkg_tar` rules)
|
||||
- Packages specific to a given service
|
||||
- Service specific outputs (`pkg_tar` rules)
|
||||
- Configuration files, if needed
|
||||
- Binaries (targeting `linux/amd64`)
|
||||
- Image configuration (`oci_image` rules)
|
||||
- Environment variables
|
||||
- Binaries (targeting `linux/amd64`)
|
||||
- Image configuration (`oci_image` rules)
|
||||
- Environment variables
|
||||
- Entrypoint
|
||||
- Image tests (`container_structure_test` rules)
|
||||
- Image tests (`container_structure_test` rules)
|
||||
- Check for correct permissions
|
||||
- Check presence of necessary packages
|
||||
- Check presence of necessary packages
|
||||
- Check that binaries are runnable inside the image
|
||||
- Default publishing target (`oci_push` rules)
|
||||
- Default publishing target (`oci_push` rules)
|
||||
- They all refer to our internal registry.
|
||||
- Please note that only enterprise variant is published.
|
||||
- Please note that only enterprise variant is published.
|
||||
|
||||
The first two layers are handled by Wolfi and the rest if handled by Bazel.
|
||||
|
||||
### Wolfi
|
||||
### Wolfi
|
||||
|
||||
See [the dedicated page for Wolfi](../wolfi/index.md).
|
||||
See [the dedicated page for Wolfi](../wolfi/index.md).
|
||||
|
||||
### Bazel
|
||||
|
||||
@ -65,7 +65,7 @@ pkg_tar(
|
||||
)
|
||||
```
|
||||
|
||||
Will create a tarball containing the outputs from the `:frontend` target, which can then be added to an image, through the `tars` attribute of the `oci_image` rule. Example:
|
||||
Will create a tarball containing the outputs from the `:frontend` target, which can then be added to an image, through the `tars` attribute of the `oci_image` rule. Example:
|
||||
|
||||
```
|
||||
oci_image(
|
||||
@ -75,9 +75,9 @@ oci_image(
|
||||
)
|
||||
```
|
||||
|
||||
We can add this way as many tarballs we want. In practice, it's best to prefer having multiple smaller tarballs instead of of a big one, as it enabled to cache them individually, to avoid having to rebuild all of them on a tiny change.
|
||||
We can add this way as many tarballs we want. In practice, it's best to prefer having multiple smaller tarballs instead of of a big one, as it enabled to cache them individually, to avoid having to rebuild all of them on a tiny change.
|
||||
|
||||
The `oci_image` rule is used to express other aspect of the image we're building, such as the `base` image to use, the `entry_point`, environment variables and which `user` should the image run the entry point with. Example:
|
||||
The `oci_image` rule is used to express other aspect of the image we're building, such as the `base` image to use, the `entry_point`, environment variables and which `user` should the image run the entry point with. Example:
|
||||
|
||||
```
|
||||
oci_image(
|
||||
@ -96,11 +96,11 @@ oci_image(
|
||||
)
|
||||
```
|
||||
|
||||
💡 Convention: we define environment variables on the the `oci_image` rule. We could hypothetically define some of them in the base image, on the Wolfi layer, but we much prefer to have everything easily readable in the Buildfile of a given service.
|
||||
💡 Convention: we define environment variables on the the `oci_image` rule. We could hypothetically define some of them in the base image, on the Wolfi layer, but we much prefer to have everything easily readable in the Buildfile of a given service.
|
||||
|
||||
The definition for `@wolfi_base` (and other images) is located in [`dev/oci_deps.bzl`](https://sourcegraph.com/github.com/sourcegraph/sourcegraph/-/blob/dev/oci_deps.bzl).
|
||||
The definition for `@wolfi_base` (and other images) is located in [`dev/oci_deps.bzl`](https://sourcegraph.com/github.com/sourcegraph/sourcegraph/-/blob/dev/oci_deps.bzl).
|
||||
|
||||
Once we have an image being defined, we need an additional rule to turn it into a tarball that can be fed to `docker load` and later on be published. It defines the default tags for that image. Example:
|
||||
Once we have an image being defined, we need an additional rule to turn it into a tarball that can be fed to `docker load` and later on be published. It defines the default tags for that image. Example:
|
||||
|
||||
```
|
||||
oci_tarball(
|
||||
@ -110,7 +110,7 @@ oci_tarball(
|
||||
)
|
||||
```
|
||||
|
||||
At this point, we can also write [container tests](https://github.com/GoogleContainerTools/container-structure-test), with the `container_structure_test` rule:
|
||||
At this point, we can also write [container tests](https://github.com/GoogleContainerTools/container-structure-test), with the `container_structure_test` rule:
|
||||
|
||||
```
|
||||
container_structure_test(
|
||||
@ -140,24 +140,24 @@ commandTests:
|
||||
exitCode: 0
|
||||
```
|
||||
|
||||
We can now build this image _locally_ and run those tests as well (please note that if you're working locally on a Linux/amd64 machine, you don't need the `--config darwin-docker` flag).
|
||||
We can now build this image _locally_ and run those tests as well.
|
||||
|
||||
💡 The image building process is much faster than the old Docker build scripts, and because most actions are cached, this makes it very easy to iterate locally on both the image definition and the container structure tests.
|
||||
|
||||
Example:
|
||||
Example:
|
||||
|
||||
```
|
||||
# Create a tarball that can be loaded in Docker of the worker service:
|
||||
bazel build //cmd/worker:image_tarball --config darwin-docker
|
||||
bazel build //cmd/worker:image_tarball
|
||||
|
||||
# Load the image in Docker:
|
||||
docker load --input $(bazel cquery //cmd/worker:image_tarball --config darwin-docker --output=files)
|
||||
# Load the image in Docker:
|
||||
docker load --input $(bazel cquery //cmd/worker:image_tarball --output=files)
|
||||
|
||||
# Run the container structure tests
|
||||
bazel test //cmd/worker:image_test --config darwin-docker
|
||||
# Run the container structure tests
|
||||
bazel test //cmd/worker:image_test
|
||||
```
|
||||
|
||||
Finally, _if and only if_ we want our image to be released on registries, we need to add the `oci_push` rule. It will take care of definining which registry to push on, as well as tagging the image, through a process referred as `stamping` that we will cover a bit further.
|
||||
Finally, _if and only if_ we want our image to be released on registries, we need to add the `oci_push` rule. It will take care of definining which registry to push on, as well as tagging the image, through a process referred as `stamping` that we will cover a bit further.
|
||||
|
||||
Apart from the `image` attribute which refers to the above `oci_rule`, `repository` refers to the internal (development) registry. Example:
|
||||
|
||||
@ -170,7 +170,7 @@ oci_push(
|
||||
)
|
||||
```
|
||||
|
||||
### Pushing images on registries
|
||||
### Pushing images on registries
|
||||
|
||||
Image are never pushed anywhere, unless we are on the `main` branch. Because we are definining a `container_structure_test` rulee, the `bazel test //...` job in CI will always build your image, even in branches. They will just be cached and never pushed.
|
||||
|
||||
@ -178,14 +178,14 @@ On the `main` branch (or if branch is `main_dry_run` runtype), a final CI job, n
|
||||
|
||||
### Stamping
|
||||
|
||||
Stamping refers to the process of marking artifacts in varied ways, so we can identify and how it was produced. It used at various levels in our pipeline, with the most two notables ones being the `Version` global that we ship within all our Go binaries and the image tags.
|
||||
Stamping refers to the process of marking artifacts in varied ways, so we can identify and how it was produced. It used at various levels in our pipeline, with the most two notables ones being the `Version` global that we ship within all our Go binaries and the image tags.
|
||||
|
||||
Example of stamps for Go rules:
|
||||
Example of stamps for Go rules:
|
||||
|
||||
```
|
||||
go_library(
|
||||
name = "worker_lib",
|
||||
# (...)
|
||||
# (...)
|
||||
x_defs = {
|
||||
"github.com/sourcegraph/sourcegraph/internal/version.version": "{STABLE_VERSION}",
|
||||
"github.com/sourcegraph/sourcegraph/internal/version.timestamp": "{VERSION_TIMESTAMP}",
|
||||
@ -200,5 +200,4 @@ go build \
|
||||
-ldflags "-X github.com/sourcegraph/sourcegraph/internal/version.version=$VERSION -X github.com/sourcegraph/sourcegraph/internal/version.timestamp=$(date +%s)" # (...)
|
||||
```
|
||||
|
||||
When we are building and testing our targets, we do not stamp our binaries with any specific versions. This enables to cache all outputs. But when we're releasing them, we do want to stamp them before releasing them in the wild.
|
||||
|
||||
When we are building and testing our targets, we do not stamp our binaries with any specific versions. This enables to cache all outputs. But when we're releasing them, we do want to stamp them before releasing them in the wild.
|
||||
|
||||
@ -2,12 +2,12 @@
|
||||
|
||||
## General
|
||||
|
||||
### `bazel configure` prints out a warning about TSConfig
|
||||
### `sg bazel configure` prints out a warning about TSConfig
|
||||
|
||||
Everytime you run `bazel configure`, you'll see a warning:
|
||||
Everytime you run `sg bazel configure`, you'll see a warning:
|
||||
|
||||
```
|
||||
$ bazel configure
|
||||
$ sg bazel configure
|
||||
Updating BUILD files for protobuf, go, javascript
|
||||
2023/11/16 12:32:52 Failed to load base tsconfig file @sourcegraph/tsconfig: open /Users/thorstenball/work/sourcegraph/@sourcegraph/tsconfig: no such file or directory
|
||||
```
|
||||
@ -33,41 +33,53 @@ By default, JetBrains IDEs such as GoLand will try and index the files in your p
|
||||
|
||||
There is no reason to index these files, so you can just exclude them from indexing by right-clicking artifact directories, then choosing **Mark directory as** → **Excluded** from the context menu. A restart is required to stop the indexing process.
|
||||
|
||||
### My local `bazel configure` or `./dev/ci/bazel-prechecks.sh` run has diff with a result of Bazel CI step
|
||||
### My local `sg bazel configure` or `./dev/ci/bazel-prechecks.sh` run has diff with a result of Bazel CI step
|
||||
|
||||
This could happen when there are any files which are not tracked by Git. These files affect the run of `bazel configure` and typically add more items to `BUILD.bazel` file.
|
||||
This could happen when there are any files which are not tracked by Git. These files affect the run of `sg bazel configure` and typically add more items to `BUILD.bazel` file.
|
||||
|
||||
Solution: run `git clean -ffdx` then run `bazel configure` again.
|
||||
Solution: run `git clean -ffdx` then run `sg bazel configure` again.
|
||||
|
||||
### How do I clean up all local Bazel cache?
|
||||
|
||||
1. The simplest way to clean up the cache is to use the clean command: `bazel clean`. This command will remove all output files and the cache in the bazel-* directories within your workspace. Use the `--expunge` flag to remove the entire working tree, including the cache directory, and force a full rebuild.
|
||||
2. To manually clear the global Bazel cache, you need to remove the respective folders from your machine. On macOS, the global cache is typically located at either `~/.cache/bazel` or `/var/tmp/_bazel_$(whoami)`.
|
||||
|
||||
### Where do I fine Bazel rules locally on disk?
|
||||
### Where do I find Bazel rules locally on disk?
|
||||
|
||||
Use `bazel info output_base` to find the output base directory. From there go to the `external` folder to find Bazel rules saved locally.
|
||||
|
||||
### How do I build a container on MacOS
|
||||
|
||||
Our containers are only built for `linux/amd64`, therefore we need to cross-compile on MacOS to produce correct images. To simplify this process, a configuration flag is available: `--config darwin-docker` to swap the toolchains for you.
|
||||
Our containers are only built for `linux/amd64`, therefore we need to cross-compile on MacOS to produce correct images. This is automatically handled by Bazel, so there should be no difference between the command to build containers on Linux and MacOS.
|
||||
|
||||
Example:
|
||||
|
||||
```
|
||||
# Create a tarball that can be loaded in Docker of the worker service:
|
||||
bazel build //cmd/worker:image_tarball --config darwin-docker
|
||||
bazel build //cmd/worker:image_tarball
|
||||
|
||||
# Load the image in Docker:
|
||||
docker load --input $(bazel cquery //cmd/worker:image_tarball --config darwin-docker --output=files)
|
||||
docker load --input $(bazel cquery //cmd/worker:image_tarball --output=files)
|
||||
```
|
||||
|
||||
You can also use the same configuration flag to run the container tests on MacOS:
|
||||
|
||||
```
|
||||
bazel test //cmd/worker:image_test --config darwin-docker
|
||||
bazel test //cmd/worker:image_test
|
||||
```
|
||||
|
||||
### I am not able to run image tests locally as Docker is not detected
|
||||
|
||||
If you get an error like:
|
||||
|
||||
```
|
||||
time="2024-02-28T06:31:07Z" level=fatal msg="error loading oci layout into daemon: error loading image: Cannot connect to the Docker daemon at unix:///var/run/docker.sock. Is the docker daemon running?, %!s(MISSING)"
|
||||
```
|
||||
|
||||
It might be because Docker Desktop was configured to use a different Docker socket during installation.
|
||||
|
||||
To fix this error, enable the checkbox under **Docker Desktop > Settings > Advanced > Allow the default Docker socket to be used (requires password)** and then restart Docker.
|
||||
|
||||
### Can I run integration tests (`bazel test //testing/...`) locally?
|
||||
|
||||
At the time of writing this documentation, it's not possible to do so, because we need to cross compile to produce `linux/amd64` container images, but the test runners need to run against your host architecture. If your host isn't `linux/amd64` you won't be able to run those tests.
|
||||
@ -125,10 +137,10 @@ Bazel uses `xcrun` to locate the SDK and toolchain for iOS/Mac compilation and x
|
||||
|
||||
Nonetheless, there is a workaround! Pass the following CLI flag when you try to build a target `--macos_sdk_version=13.3`. With the flag bazel should be able to find the MacOS SDK and you should not get the error anymore. It's recommended to add `build --macos_sdk_version=13.3` to your `.bazelrc` file so that you don't have to add the CLI flag every time you invoke a build.
|
||||
|
||||
### I see `error: unable to open mailmap at .mailmap: Too many levels of symbolic links` when running my `bazel run` target (both locally and in CI)
|
||||
### I see `error: unable to open mailmap at .mailmap: Too many levels of symbolic links` when running my `bazel run` target (both locally and in CI)
|
||||
|
||||
If you see this, it most probably means that you have a `bazel run //something` that calls `git log`. Git will look for a `.mailmap` at the root of the repository, which we do have in the monorepo. Because
|
||||
`bazel run` runs commands with a working directory which is in the runfiles, symbolic links are getting in the way.
|
||||
If you see this, it most probably means that you have a `bazel run //something` that calls `git log`. Git will look for a `.mailmap` at the root of the repository, which we do have in the monorepo. Because
|
||||
`bazel run` runs commands with a working directory which is in the runfiles, symbolic links are getting in the way.
|
||||
|
||||
While it says "error", it's to be noted that it doesn't prevent the Git command to continue.
|
||||
|
||||
@ -183,7 +195,7 @@ Any tests that make network calls on `localhost` need to be reachable from your
|
||||
|
||||
This can be achieved by adding the attribute `tags = ["requires-network"]` to the `go_test` rule in the `BUILD.bazel` file of the test directory.
|
||||
|
||||
> NOTE: make sure to run `bazel configure` after adding the tag as it will probably move it to another line. Save yourself a failing build!
|
||||
> NOTE: make sure to run `sg bazel configure` after adding the tag as it will probably move it to another line. Save yourself a failing build!
|
||||
|
||||
## Go
|
||||
|
||||
@ -217,7 +229,7 @@ INFO: 36 processes: 2 internal, 34 darwin-sandbox.
|
||||
```
|
||||
|
||||
|
||||
Solution: run `bazel configure` to update the buildfiles automatically.
|
||||
Solution: run `sg bazel configure` to update the buildfiles automatically.
|
||||
|
||||
### My go tests complains about missing testdata
|
||||
|
||||
@ -275,7 +287,7 @@ ERROR: /Users/william/code/sourcegraph/WORKSPACE:197:18: fetching crates_reposit
|
||||
Error in path: Not a regular file: /Users/william/code/sourcegraph/docker-images/syntax-highlighter/fake.lock
|
||||
ERROR: Error computing the main repository mapping: no such package '@crate_index//': Not a regular file: /Users/william/code/sourcegraph/docker-images/syntax-highlighter/Cargo.Bazel.lock
|
||||
```
|
||||
The error happens when the file specified in the lockfiles attribute of `crates_repository` (see WORKSPACE file for the definition) does not exist on disk. Currently this rule does not generate the file, instead it just generates the _content_ of the file. So to get passed this error you should create the file `touch docker-images/syntax-highlighter/Cargo.Bazel.lock`. With the file create it we can now populate `Cargo.Bazel.lock` with content using bazel by running `CARGO_BAZEL_REPIN=1 bazel sync --only=crate_index`.
|
||||
The error happens when the file specified in the lockfiles attribute of `crates_repository` (see WORKSPACE file for the definition) does not exist on disk. Currently this rule does not generate the file, instead it just generates the _content_ of the file. So to get passed this error you should create the file `touch docker-images/syntax-highlighter/Cargo.Bazel.lock`. With the file create it we can now populate `Cargo.Bazel.lock` with content using bazel by running `sg bazel configure rustdeps`.
|
||||
|
||||
### When I build `syntax-highlighter` it complains that the current `lockfile` is out of date
|
||||
The error will look like this:
|
||||
@ -308,29 +320,23 @@ ERROR: Error computing the main repository mapping: no such package '@crate_inde
|
||||
|
||||
The current `lockfile` is out of date for 'crate_index'. Please re-run bazel using `CARGO_BAZEL_REPIN=true` if this is expected and the lockfile should be updated.
|
||||
```
|
||||
Bazel uses a separate lock file to keep track of the dependencies and needs to be updated. To update the `lockfile` run `CARGO_BAZEL_REPIN=1 CARGO_BAZEL_REPIN_ONLY=crate_index bazel sync --only=crate_index`. This command takes a while to execute as it fetches all the dependencies specified in `Cargo.lock` and populates `Cargo.Bazel.lock`.
|
||||
Bazel uses a separate lock file to track the dependencies, which need to be updated. To update the `lockfile` run `CARGO_BAZEL_REPIN_ONLY=crate_index sg bazel configure rustdeps`. This command takes a while to execute as it fetches all the dependencies specified in `Cargo.lock` and populates `Cargo.Bazel.lock`. This command _might also fail_ in that case [see](#bazel-sync-authentication-failure-when-cloning-syntect).
|
||||
|
||||
### `syntax-highlighter` fails to build and has the error `failed to resolve: use of undeclared crate or module`
|
||||
The error looks something like this:
|
||||
```
|
||||
error[E0433]: failed to resolve: use of undeclared crate or module `scip_treesitter_languages`
|
||||
--> docker-images/syntax-highlighter/src/main.rs:56:5
|
||||
|
|
||||
56 | scip_treesitter_languages::highlights::CONFIGURATIONS
|
||||
| ^^^^^^^^^^^^^^^^^^^^^^^^^ use of undeclared crate or module `scip_treesitter_languages`
|
||||
|
||||
error[E0433]: failed to resolve: use of undeclared crate or module `scip_treesitter_languages`
|
||||
error[E0433]: failed to resolve: use of undeclared crate or module `tree_sitter_all_languages`
|
||||
--> docker-images/syntax-highlighter/src/main.rs:57:15
|
||||
|
|
||||
57 | .get(&scip_treesitter_languages::parsers::BundledParser::Go);
|
||||
| ^^^^^^^^^^^^^^^^^^^^^^^^^ use of undeclared crate or module `scip_treesitter_languages`
|
||||
57 | .get(&tree_sitter_all_languages::ParserId::Go);
|
||||
| ^^^^^^^^^^^^^^^^^^^^^^^^^ use of undeclared crate or module `tree_sitter_all_languages`
|
||||
|
||||
error: aborting due to 2 previous errors
|
||||
```
|
||||
Bazel doesn't know about the module/crate being use in the rust code. If you do a git blame `Cargo.toml` you'll probably see that a new dependency has been added, but the build files were not updated. There are two ways to solve this:
|
||||
1. Run `bazel configure` and `CARGO_BAZEL_REPIN=1 CARGO_BAZEL_REPIN_ONLY=crate_index bazel sync --only=crate_index`. Once the commands have completed you can check that the dependency has been picked up and syntax-highlighter can be built by running `bazel build //docker-images/syntax-highlighter/...`. **Note** this will usually work if the dependency is an *external* dependency.
|
||||
1. Run `sg bazel configure builds rustdeps`. Once the commands have completed you can check that the dependency has been picked up and syntax-highlighter can be built by running `bazel build //docker-images/syntax-highlighter/...`. **Note** this will usually work if the dependency is an *external* dependency.
|
||||
2. You're going to have to update the `BUILD.bazel` file yourself. Which one you might ask? From the above error we can see the file `src/main.rs` is where the error is encountered, so we need to tell *its BUILD.bazel* about the new dependency.
|
||||
For the above dependency, the crate is defined in `docker-images/syntax-highlighter/crates`. You'll also see that each of those crates have their own `BUILD.bazel` files in them, which means we can reference them as targets! Take a peak at `scip-treesitter-languages` `BUILD.bazel` file and take note of the name - that is its target. Now that we have the name of the target we can add it as a dep to `docker-images/syntax-highlighter`. In the snippet below the `syntax-highlighter` `rust_binary` rule is updated with the `scip-treesitter-languages` dependency. Note that we need to refer to the full target path when adding it to the dep list in the `BUILD.bazel` file.
|
||||
For the above dependency, the crate is defined in `docker-images/syntax-highlighter/crates`. You'll also see that each of those crates have their own `BUILD.bazel` files in them, which means we can reference them as targets! Take a peak at `tree-sitter-all-languages` `BUILD.bazel` file and take note of the name - that is its target. Now that we have the name of the target we can add it as a dep to `docker-images/syntax-highlighter`. In the snippet below the `syntax-highlighter` `rust_binary` rule is updated with the `tree-sitter-all-languages` dependency. Note that we need to refer to the full target path when adding it to the dep list in the `BUILD.bazel` file.
|
||||
```
|
||||
rust_binary(
|
||||
name = "syntect_server",
|
||||
@ -343,11 +349,47 @@ rust_binary(
|
||||
normal = True,
|
||||
) + [
|
||||
"//docker-images/syntax-highlighter/crates/sg-syntax:sg-syntax",
|
||||
"//docker-images/syntax-highlighter/crates/scip-treesitter-languages:scip-treesitter-languages",
|
||||
"//docker-images/syntax-highlighter/crates/tree-sitter-all-languages:tree-sitter-all-languages",
|
||||
],
|
||||
)
|
||||
```
|
||||
|
||||
### `bazel sync` authentication failure when cloning `syntect`
|
||||
|
||||
When repinning dependencies with `CARGO_BAZEL_REPIN_ONLY=crate_index sg bazel configure rustdeps` it may fail with the following Cargo error:
|
||||
|
||||
```
|
||||
STDERR ------------------------------------------------------------------------
|
||||
|
||||
Updating crates.io index
|
||||
Updating git repository `https://github.com/sourcegraph/syntect`
|
||||
error: failed to get `syntect` as a dependency of package `sg-syntax v0.1.0 (/var/folders/1r/5z42n9p52zv8rfp93gxc1vfr0000gn/T/.tmpyhlucq/crates/sg-syntax)`
|
||||
|
||||
Caused by:
|
||||
failed to load source for dependency `syntect`
|
||||
|
||||
Caused by:
|
||||
Unable to update https://github.com/sourcegraph/syntect?rev=7e02c5b4085e6d935b960b8106cdd85da04532d2#7e02c5b4
|
||||
|
||||
Caused by:
|
||||
failed to clone into: /private/var/tmp/_bazel_william/c92ec739369034d3064b6df55c419545/external/crate_index/.cargo_home/git/db/syntect-383b2f29eb0ef0d0
|
||||
|
||||
Caused by:
|
||||
failed to authenticate when downloading repository: ssh://git@github.com/sourcegraph/syntect
|
||||
|
||||
* attempted ssh-agent authentication, but no usernames succeeded: `git`
|
||||
|
||||
if the git CLI succeeds then `net.git-fetch-with-cli` may help here
|
||||
https://doc.rust-lang.org/cargo/reference/config.html#netgit-fetch-with-cli
|
||||
|
||||
Caused by:
|
||||
no authentication methods succeeded
|
||||
|
||||
Error: Failed to update lockfile: exit status: 101
|
||||
```
|
||||
|
||||
You might be able to Git SSH clone that repository locally, yet in Bazel Cargo, it fails. This is because Bazel Cargo doesn't use your `~/.ssh/config` file and thus can't use your SSH private key. The error says you can set `net.git-fetch-with-cli` in `Cargo.toml` or configure a credential helper. All cargo settings also have environment variable variants, so you can do the repinning with `CARGO_NET_GIT_FETCH_WITH_CLI=true sg bazel configure rustdeps` without setting the value in the `Cargo.toml`.
|
||||
|
||||
## Docs
|
||||
|
||||
### `//docs:test` is not finding my documents after I added `BUILD.bazel` file in a child directory
|
||||
|
||||
@ -12,6 +12,7 @@ Sourcegraph uses [Bazel](https://bazel.build) as its build system. Reach out on
|
||||
- **Context specific**
|
||||
- [Bazel and Go](./go.md)
|
||||
- [Bazel and client](./web.md)
|
||||
- [Bazel and Rust](./rust.md)
|
||||
- [Overview of the Bazel configuration for client](./web_overview.md)
|
||||
- [Bazel and container images](./containers.md)
|
||||
- **How-tos**
|
||||
|
||||
50
doc/dev/background-information/bazel/rust.md
Normal file
50
doc/dev/background-information/bazel/rust.md
Normal file
@ -0,0 +1,50 @@
|
||||
# Bazel for Rust
|
||||
|
||||
Also checkout the [FAQ](faq.md) for common issues and solutions.
|
||||
|
||||
## TL;DR
|
||||
|
||||
- Commands:
|
||||
- `sg bazel configure rustdeps` after changing workspace members or dependencies.
|
||||
- Setting `CARGO_BAZEL_ISOLATED=0` can be set if repinning is too slow, if doing it frequently in local development.
|
||||
- `CARGO_BAZEL_REPIN=<crate name> sg bazel configure rustdeps` after adding/updating a dependency.
|
||||
|
||||
## Overview
|
||||
|
||||
The rules interfacing Rust are named [`rules_rust`](https://github.com/bazelbuild/rules_rust/) and they provide all the plumbing to call the Rust compiler and run the tests.
|
||||
|
||||
Bazel and Rust works slightly differently to Bazel and Go. Unlike with Go, `BUILD.bazel` files are not updated with `sg bazel configure` (they must be updated/configured/created by hand), and instead of there being one `BUILD.bazel` file per directory, it's one per workspace member.
|
||||
There exists [gazelle_rust](https://github.com/Calsign/gazelle_rust), a plugin for [Gazelle](https://github.com/bazelbuild/bazel-gazelle) which is invoked via `sg bazel configure`, that may address the first point but we have decided not to invest in using it at the time of writing.
|
||||
|
||||
## Rules for Rust
|
||||
|
||||
The rules you'll see for Rust are [`rust_binary`](https://bazelbuild.github.io/rules_rust/defs.html#rust_binary), [`rust_library`](https://bazelbuild.github.io/rules_rust/defs.html#rust_library), [`rust_test`](https://bazelbuild.github.io/rules_rust/defs.html#rust_test) and [`rust_proc_macro`](https://bazelbuild.github.io/rules_rust/defs.html#rust_proc_macro).
|
||||
|
||||
Each rule type will have a certain set of common attribute values between them for dependency and proc-macro resolution, alongside others such as `name` and rule-specific attributes with values specific to those particular instances that are each briefly explained in the docs for the relevant rules, found at the links above.
|
||||
|
||||
`rust_binary` and `rust_library` targets have the following displayed attribute values in common:
|
||||
|
||||
```python
|
||||
aliases = aliases(),
|
||||
proc_macro_deps = all_crate_deps(
|
||||
proc_macro = True,
|
||||
),
|
||||
deps = all_crate_deps(
|
||||
normal = True,
|
||||
),
|
||||
```
|
||||
|
||||
while `rust_test` targets have the following displayed attribute values in common:
|
||||
|
||||
```python
|
||||
aliases = aliases(
|
||||
normal_dev = True,
|
||||
proc_macro_dev = True,
|
||||
),
|
||||
proc_macro_deps = all_crate_deps(
|
||||
proc_macro_dev = True,
|
||||
),
|
||||
deps = all_crate_deps(
|
||||
normal_dev = True,
|
||||
),
|
||||
```
|
||||
@ -1,245 +0,0 @@
|
||||
# using gRPC alongside REST for internal APIs
|
||||
|
||||
New internal APIs must have both gRPC and REST implementations so that we can provide a grace period for customers. The
|
||||
REST implementation should use
|
||||
the [canonical JSON representation of the generated protobuf structs](https://protobuf.dev/programming-guides/proto3/#json)
|
||||
in the HTTP body for arguments and responses.
|
||||
|
||||
> NOTE: An "internal" API is one that's solely used for intra-service communication/RPCs (think `searcher` fetching an archive from `gitserver`). Internal APIs don't include things like the graphQL API that external people can use (including our web interface).
|
||||
|
||||
We expect only to maintain both implementations for the `5.1.X` release in June. Afterward, we'll only use the gRPC API and can delete the redundant REST implementations.
|
||||
|
||||
> NOTE: Even after the `5.1.X` release, we can't translate some endpoints into gRPC in the first place. Examples include endpoints used by the git protocol directly and services we have no control over that don't support gRPC (such as Postgres). See the [gRPC June 2023 milestone issue](https://github.com/sourcegraph/sourcegraph/issues/51069) for more details.
|
||||
|
||||
## simple example
|
||||
|
||||
The following example demonstrates how to implement a simple service in Go that provides both gRPC and REST APIs, using
|
||||
the [canonical JSON representation of the generated Protobuf structs](https://protobuf.dev/programming-guides/proto3/#json).
|
||||
|
||||
**Notes**:
|
||||
|
||||
- The Go service
|
||||
uses [google.golang.org/protobuf/encoding/protojson](https://google.golang.org/protobuf/encoding/protojson) to Marshal
|
||||
and Unmarshal Protobuf structs to/from JSON. The standard "encoding/json" package should **not** be used here: it
|
||||
doesn't correctly operate on protobuf structs.
|
||||
- In this example, the gRPC and REST implementations share a helper function that does the actual work. This is not
|
||||
strictly required, but it's a good practice to follow (especially if the service is more complex than this example).
|
||||
|
||||
### gRPC definition
|
||||
|
||||
```proto
|
||||
syntax = "proto3";
|
||||
|
||||
package greeting;
|
||||
|
||||
service GreeterService {
|
||||
rpc SayHello (HelloRequest) returns (HelloReply);
|
||||
}
|
||||
|
||||
message HelloRequest {
|
||||
string name = 1;
|
||||
}
|
||||
|
||||
message HelloReply {
|
||||
string message = 1;
|
||||
}
|
||||
```
|
||||
|
||||
### generate the Go protobuf structs
|
||||
|
||||
> NOTE: Unless you're adding an entirely new service to sourcegraph/sourcegraph, you should be able to reuse
|
||||
the `buf.gen.yaml` files that have already been written for you. For the purposes of this example, we'll write a new
|
||||
one.
|
||||
|
||||
Create the following buf configuration file:
|
||||
|
||||
#### buf.gen.yaml
|
||||
|
||||
The buf configuration file generates the Go code for the Protobuf definition. This file specifies the plugins
|
||||
to use and the output directory for the generated code. The generated code includes the Protobuf structs we can
|
||||
reuse in gRPC and REST implementations.
|
||||
|
||||
```yaml
|
||||
# Configuration file for https://buf.build/, which we use for Protobuf code generation.
|
||||
version: v1
|
||||
plugins:
|
||||
- plugin: buf.build/protocolbuffers/go:v1.29.1
|
||||
out: .
|
||||
opt:
|
||||
- paths=source_relative
|
||||
- plugin: buf.build/grpc/go:v1.3.0
|
||||
out: .
|
||||
opt:
|
||||
- paths=source_relative
|
||||
```
|
||||
|
||||
Now, run `sg generate buf` to use the above configuration file to generate the Go code for the protobuf definition
|
||||
above. That command creates the following files:
|
||||
|
||||
#### greeter.pb.go
|
||||
|
||||
```go
|
||||
package greeter
|
||||
|
||||
type HelloRequest struct {
|
||||
// ...
|
||||
Name string `protobuf:"bytes,1,opt,name=name,proto3" json:"name,omitempty"`
|
||||
}
|
||||
|
||||
type HelloReply struct {
|
||||
// ...
|
||||
Name string `protobuf:"bytes,1,opt,name=name,proto3" json:"name,omitempty"`
|
||||
}
|
||||
|
||||
// ... (omitted)
|
||||
```
|
||||
|
||||
##### greeter_grpc.pb.go
|
||||
|
||||
```go
|
||||
package greeter
|
||||
|
||||
import (
|
||||
context "context"
|
||||
grpc "google.golang.org/grpc"
|
||||
)
|
||||
|
||||
type GreeterServiceClient interface {
|
||||
SayHello(ctx context.Context, in *HelloRequest, opts ...grpc.CallOption) (*HelloReply, error)
|
||||
}
|
||||
|
||||
// ... (omitted)
|
||||
```
|
||||
|
||||
### go service implementation
|
||||
|
||||
```go
|
||||
package main
|
||||
|
||||
import (
|
||||
"context"
|
||||
"fmt"
|
||||
"io"
|
||||
"log"
|
||||
"net"
|
||||
"net/http"
|
||||
|
||||
"github.com/gorilla/mux"
|
||||
"google.golang.org/grpc"
|
||||
"google.golang.org/grpc/codes"
|
||||
"google.golang.org/grpc/status"
|
||||
|
||||
"example.com/greeting"
|
||||
|
||||
// 🚨🚨🚨 note the use of this package instead of "encoding/json"!
|
||||
// "encoding/json" doesn't correctly serialize protobuf structs
|
||||
"google.golang.org/protobuf/encoding/protojson"
|
||||
)
|
||||
|
||||
type server struct {
|
||||
greeting.UnimplementedGreeterServiceServer
|
||||
}
|
||||
|
||||
func (s *server) SayHello(ctx context.Context, in *greeting.HelloRequest) (*greeting.HelloReply, error) {
|
||||
reply, err := getReply(ctx, in.GetName())
|
||||
if err != nil {
|
||||
return nil, err
|
||||
}
|
||||
|
||||
return &greeting.HelloReply{Message: reply}, nil
|
||||
}
|
||||
|
||||
func main() {
|
||||
// Start gRPC server
|
||||
lis, err := net.Listen("tcp", ":50051")
|
||||
if err != nil {
|
||||
log.Fatalf("failed to listen: %v", err)
|
||||
}
|
||||
grpcServer := grpc.NewServer()
|
||||
greeting.RegisterGreeterServiceServer(grpcServer, &server{})
|
||||
go func() {
|
||||
if err := grpcServer.Serve(lis); err != nil {
|
||||
log.Fatalf("failed to serve: %v", err)
|
||||
}
|
||||
}()
|
||||
|
||||
// Start REST server
|
||||
r := mux.NewRouter()
|
||||
r.HandleFunc("/sayhello", sayHelloREST).Methods("POST")
|
||||
http.ListenAndServe(":8080", r)
|
||||
}
|
||||
|
||||
func sayHelloREST(w http.ResponseWriter, r *http.Request) {
|
||||
// First, grab the arguments from the request body
|
||||
|
||||
body, err := io.ReadAll(r.Body)
|
||||
if err != nil {
|
||||
http.Error(w, fmt.Sprintf("reading request json body: %s", err.Error()), http.StatusInternalServerError)
|
||||
}
|
||||
defer r.Body.Close()
|
||||
|
||||
var req greeting.HelloRequest
|
||||
err = protojson.Unmarshal(body, &req)
|
||||
if err != nil {
|
||||
http.Error(w, "invalid request", http.StatusBadRequest)
|
||||
return
|
||||
}
|
||||
|
||||
// Next, get the reply from the shared helper function
|
||||
|
||||
reply, err := getReply(r.Context(), req.GetName())
|
||||
if err != nil {
|
||||
code, message := convertGRPCErrorToHTTPStatus(err)
|
||||
http.Error(w, message, code)
|
||||
return
|
||||
}
|
||||
|
||||
// Finally, prepare the response and send it
|
||||
|
||||
resp := &greeting.HelloReply{Message: reply}
|
||||
jsonBytes, err := protojson.Marshal(resp)
|
||||
if err != nil {
|
||||
http.Error(w, err.Error(), http.StatusInternalServerError)
|
||||
return
|
||||
}
|
||||
|
||||
w.Header().Set("Content-Type", "application/json")
|
||||
w.WriteHeader(http.StatusOK)
|
||||
w.Write(jsonBytes)
|
||||
}
|
||||
|
||||
// getReply is a helper function that we can reuse in both the gRPC and REST APIs
|
||||
// so that we don't have to duplicate the implementation logic.
|
||||
func getReply(_ context.Context, name string) (message string, err error) {
|
||||
if name == "" {
|
||||
return "", status.Error(codes.InvalidArgument, "name was not provided")
|
||||
}
|
||||
|
||||
return fmt.Sprintf("Hello, %s!", name), nil
|
||||
}
|
||||
|
||||
// convertGRPCErrorToHTTPStatus translates gRPC error codes to HTTP status codes. See
|
||||
// https://chromium.googlesource.com/external/github.com/grpc/grpc/+/refs/tags/v1.21.4-pre1/doc/statuscodes.md
|
||||
// for more information.
|
||||
func convertGRPCErrorToHTTPStatus(err error) (httpCode int, errorText string) {
|
||||
s, ok := status.FromError(err)
|
||||
if !ok {
|
||||
return http.StatusInternalServerError, err.Error()
|
||||
}
|
||||
|
||||
switch s.Code() {
|
||||
case codes.InvalidArgument:
|
||||
return http.StatusBadRequest, s.Message()
|
||||
default:
|
||||
return http.StatusInternalServerError, s.Message()
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
As you can see, this service reuses the generated protobuf structs in both the gRPC and REST APIs.
|
||||
|
||||
It also extracts the core implementation logic into a shared helper function, `getReply`, that can be reused in both interfaces. This:
|
||||
|
||||
- reduces code duplication (reducing the chance of drift in either implementation)
|
||||
- makes testing easier (we only need to test `getReply` once)
|
||||
- limits the scope of what the gRPC and REST functions are doing (only deserializing the requests and serializing the responses)
|
||||
24
doc/dev/background-information/grpc_tutorial.md
Normal file
24
doc/dev/background-information/grpc_tutorial.md
Normal file
@ -0,0 +1,24 @@
|
||||
# gRPC
|
||||
|
||||
As of Sourcegraph `5.3.X`, [gRPC](https://grpc.io/about/) has supplanted REST as our default mode of communication between our microservices for our internal APIs.
|
||||
|
||||
<Callout type="note">An "internal" API is one that's solely used for intra-service communication/RPCs (think `searcher` fetching an archive from `gitserver`). Internal APIs don't include things like the GraphQL API that external people can use (including our web interface).</Callout>
|
||||
|
||||
## gRPC Tutorial
|
||||
|
||||
The [`internal/grpc/example`](https://github.com/sourcegraph/sourcegraph/tree/main/internal/grpc/example) package in the [sourcegraph/sourcegraph monorepo](https://github.com/sourcegraph/sourcegraph) contains a simple, runnable example of a gRPC service and client. It is a good starting point for understanding how to write a gRPC service that covers the following topics:
|
||||
|
||||
- All the basic Protobuf types (e.g. primitives, enums, messages, one-ofs, etc.)
|
||||
- All the basic RPC types (e.g. unary, server streaming, client streaming, bidirectional streaming)
|
||||
- Error handling (e.g. gRPC errors, wrapping status errors, etc.)
|
||||
- Implementing a gRPC server (with proper separation of concerns)
|
||||
- Implementing a gRPC client
|
||||
- Some known footguns (non-utf8 strings, huge messages, etc.)
|
||||
- Some Sourcegraph-specific helper packages and patterns ([grpc/defaults](https://github.com/sourcegraph/sourcegraph/tree/main/internal/grpc/defaults), [grpc/streamio](https://github.com/sourcegraph/sourcegraph/tree/main/internal/grpc/streamio), etc.)
|
||||
|
||||
When going through this example for the first time, it is recommended to:
|
||||
|
||||
1. Read the protobuf definitions in [weather/v1/weather.proto](https://github.com/sourcegraph/sourcegraph/blob/main/internal/grpc/example/weather/v1/weather.proto) to get a sense of the service.
|
||||
2. Run the server and client examples in [server/](https://github.com/sourcegraph/sourcegraph/tree/main/internal/grpc/example/server) and [client/](https://github.com/sourcegraph/sourcegraph/tree/main/internal/grpc/example/client) (via [server/run-server.sh](https://github.com/sourcegraph/sourcegraph/blob/main/internal/grpc/example/server/run-server.sh) and [client/run-client.sh](https://github.com/sourcegraph/sourcegraph/blob/main/internal/grpc/example/client/run-client.sh)) respectively to see the service in action. You can see a recording of this below:
|
||||
- [](https://asciinema.org/a/wFAVGl59oxSWuLSazBgdpO5ks)
|
||||
3. Read the implementation of the [server](https://github.com/sourcegraph/sourcegraph/tree/main/internal/grpc/example/server) and [client](https://github.com/sourcegraph/sourcegraph/tree/main/internal/grpc/example/client) to get a sense of how things are implemented, and follow the explanatory comments in the code.
|
||||
@ -31,11 +31,11 @@ You can also just use [cURL](https://curl.se/) if you prefer a CLI tool.
|
||||
|
||||
The creators of major IdPs supply validators that one can use to test their SCIM implementation.
|
||||
|
||||
We used three validators when testing our implementation: two for Okta and one for Azure AD.
|
||||
We used three validators when testing our implementation: two for Okta and one for Microsoft Entra ID.
|
||||
|
||||
1. Okta SPEC test – Follow [this guide](https://developer.okta.com/docs/guides/scim-provisioning-integration-prepare/main/#test-your-scim-api) to set it up in five minutes. Tests should be green.
|
||||
2. Okta CRUD test – Follow [this guide](https://developer.okta.com/docs/guides/scim-provisioning-integration-test/main/) to set up these tests in your Runscope. This also needs access to an Okta application, which you can find [here](https://dev-433675-admin.oktapreview.com/admin/app/dev-433675_k8ssgdevorgsamlscim_1/instance/0oa1l85zn9a0tgzKP0h8/). Log in with shared credentials in 1Password. Tests should be green, except for the last ones that rely on soft deletion which we don't support yet.
|
||||
3. Azure AD validator – It's [here](https://scimvalidator.microsoft.com). It doesn't have a lot of docs. Just use "Discover my schema", then enter the endpoint (for example, https://sourcegraph.test:3443/search/.api/scim/v2) and the token you have in your settings. It should work right away, and all tests should pass.
|
||||
3. Microsoft Entra ID validator – It's [here](https://scimvalidator.microsoft.com). It doesn't have a lot of docs. Just use "Discover my schema", then enter the endpoint (for example, https://sourcegraph.test:3443/search/.api/scim/v2) and the token you have in your settings. It should work right away, and all tests should pass.
|
||||
|
||||
## Publishing on Okta
|
||||
|
||||
|
||||
@ -186,10 +186,8 @@ env:
|
||||
commands:
|
||||
gitserver:
|
||||
install: |
|
||||
config=""
|
||||
[[ $(uname) == "Darwin" ]] && config="--config darwin-docker"
|
||||
bazel build //cmd/gitserver:image_tarball ${config} && \
|
||||
docker load --input $(bazel cquery //cmd/gitserver:image_tarball ${config} --output=files)
|
||||
bazel build //cmd/gitserver:image_tarball && \
|
||||
docker load --input $(bazel cquery //cmd/gitserver:image_tarball --output=files)
|
||||
gitserver-0:
|
||||
cmd: |
|
||||
docker inspect gitserver-${GITSERVER_INDEX} >/dev/null 2>&1 && docker stop gitserver-${GITSERVER_INDEX}
|
||||
|
||||
@ -8,3 +8,4 @@ Guidance and documentation about writing database interactions within the Source
|
||||
- [Batch operations](batch_operations.md)
|
||||
- [Materialized cache](materialized_cache.md)
|
||||
- [Locking behavior](locking_behavior.md)
|
||||
- [Upgrades and Migrator Design](upgrades_and_migrator_design.md)
|
||||
|
||||
@ -0,0 +1,352 @@
|
||||
# Upgrades and Migrator Design
|
||||
|
||||
<p className="subtitle">This doc is based on a preface for [RFC 850 WIP: Improving The Upgrade
|
||||
Experience](https://docs.google.com/document/d/1ne8ai60iQnZfaYuB7QLDMIWgU5188Vn4_HBeUQ3GASY/edit)
|
||||
and acts as a summary of the current design of our upgrade and database schema
|
||||
management design. Subsequently additions have been made. The docs initial aim was to provide general information about the
|
||||
relationship of our migrator service to our deployment types and
|
||||
migrator's dependencies during the release process.</p>
|
||||
|
||||
## Migrator Overview
|
||||
|
||||
The `migrator` service is a short-lived container responsible for managing
|
||||
Sourcegraph's databases (`pgsql` (*also referred to as frontend*), `codeintel-db`,
|
||||
and `codeinsights-db`), and running schema migrations during startup and upgrades.
|
||||
|
||||
Its design accounts for various unique characteristics of
|
||||
versioning and database management at Sourcegraph. Specifically graphical
|
||||
schema migrations, out-of-band migrations, and periodic schema migration squashing.
|
||||
|
||||
Sourcegraph utilizes a [directed acyclic graph](https://github.com/sourcegraph/sourcegraph/pull/30664)
|
||||
of migration definitions, rather than a linear chain. In Sourcegraph's early days when schema migrations
|
||||
were applied linearly, schema changes were frequent enough that schema changes generally conflicted with
|
||||
the master branch by the time a PR passed CI. Moving to a graph of migrations means, devs won't need to
|
||||
worry about other teammates concurrent schema changes unless they are working on the same table.
|
||||
|
||||
Similarly [squashing](#squashing-migrations) of schema migrations into a root definition reduced the number of migrations run on startup,
|
||||
alleviating a common issue in which frequent transaction locks caused failed migration on Sourcegraph startup.
|
||||
You can learn more in our [migrations overview docs](/migrations_overview#in-band-migrations).
|
||||
Information on out of bound migrations can also be found there.
|
||||
|
||||
|
||||
Migrator with its relevant artifacts in the sourcegraph/sourcegraph repo can be viewed as an orchestrator with two special functions --
|
||||
|
||||
1. Migrator constructs migration plans given version ranges and a table
|
||||
of migrations which have been successfully applied (each schema has
|
||||
a table to track applied migrations within that schema). This logic
|
||||
is supported by a variety of files generated during releases and
|
||||
depends on the parent/child metadata of migrations generated via the
|
||||
sg migration tool.
|
||||
|
||||
2. Migrator manages out-of-band migrations. These are data migrations
|
||||
that must be run within specific schema boundaries. Running OOB
|
||||
migrations at/after the deprecated version is unsupported. Migrator
|
||||
ensures that the necessary OOB migrations are run at [stopping
|
||||
points](https://sourcegraph.com/github.com/sourcegraph/sourcegraph/-/blob/internal/oobmigration/upgrade.go?L32-42)
|
||||
in a multiversion upgrade -- learn more
|
||||
[here](https://about.sourcegraph.com/blog/introducing-migrator-service).
|
||||
|
||||
### CLI design
|
||||
|
||||
Migrator is designed with a CLI tool interface -- taking various commands to alter
|
||||
the state of the database and apply necessary schema changes. This
|
||||
design was initially implemented as a tool for TS team members to assist
|
||||
in multiversion upgrades and because it could easily be included over
|
||||
multiple deployment methods as a containerized process run separately
|
||||
from the frontend during startup ([which originally caused
|
||||
issues](https://about.sourcegraph.com/blog/introducing-migrator-service)).
|
||||
This replaced earlier go/migrate based strategies which ran in the
|
||||
frontend on startup. While the migrator can operate as a CLI tool, it's
|
||||
containerized as if it was another application which allows it to be run
|
||||
as an initContainer (in Kubernetes deployments) or as a dependent
|
||||
service (for Docker Compose deployments) to ensure that the necessary
|
||||
migrations are applied before startup of the application proper.
|
||||
Check out [RFC 469](https://docs.google.com/document/d/1_wqvNbEGhMzu45CHZNrLQYys7gl0AtVpLluGp4cbQKk/edit#heading=h.ddeuyk4t99yx) to learn more.
|
||||
|
||||
### Important Commands
|
||||
|
||||
The most important migrator commands are `up` and `upgrade`, with a notable mention to `drift`:
|
||||
|
||||
- **Up** : The default command of migrator, `up` ensures that
|
||||
for a given version of the migrator, every migration defined at
|
||||
that build has been successfully applied in the connected database,
|
||||
this is specifically important to ensure *patch version migrations are run*.
|
||||
***This must be run with the target version migrator image/build**.*
|
||||
If migrator and frontend pods are deployed in version lockstep, `up`
|
||||
ensures that ALL migrations required by the frontend will be successfully applied prior to boot.
|
||||
This is a syntactic sugar over a more internal `upto` command.
|
||||
- **Upgrade**: `upgrade` runs all migrations defined between two minor versions
|
||||
of Sourcegraph and requires that other services which may access the
|
||||
database are brought down. Before running, the database is checked
|
||||
for and schema drifts in order to prevent a failure while attempting
|
||||
a migration. `upgrade` relies on `stitched-migration-graph.json`.
|
||||
- **Drift**: This command pulls runs a diff between the current database
|
||||
schema and an expected definition packaged in migrator during the
|
||||
release process. Many migrator operations run this check before
|
||||
proceeding to ensure the database is in the expected state.
|
||||
|
||||
In general, the `up` command can be thought of as a **standard** upgrade
|
||||
(rolling upgrades with no downtime) while the upgrade command is what
|
||||
enables **multiversion** upgrades. In part, `up` was designed to maintain
|
||||
our previous upgrade policy and is thus run as an initContainer (or
|
||||
initContainer-like mechanism) of the frontend, i.e. between two versions
|
||||
of Sourcegraph, the antecedent Sourcegraph services will continue to
|
||||
work after the consequent version's migrations have been applied.
|
||||
|
||||
## Current Startup Dependency
|
||||
|
||||
|
||||
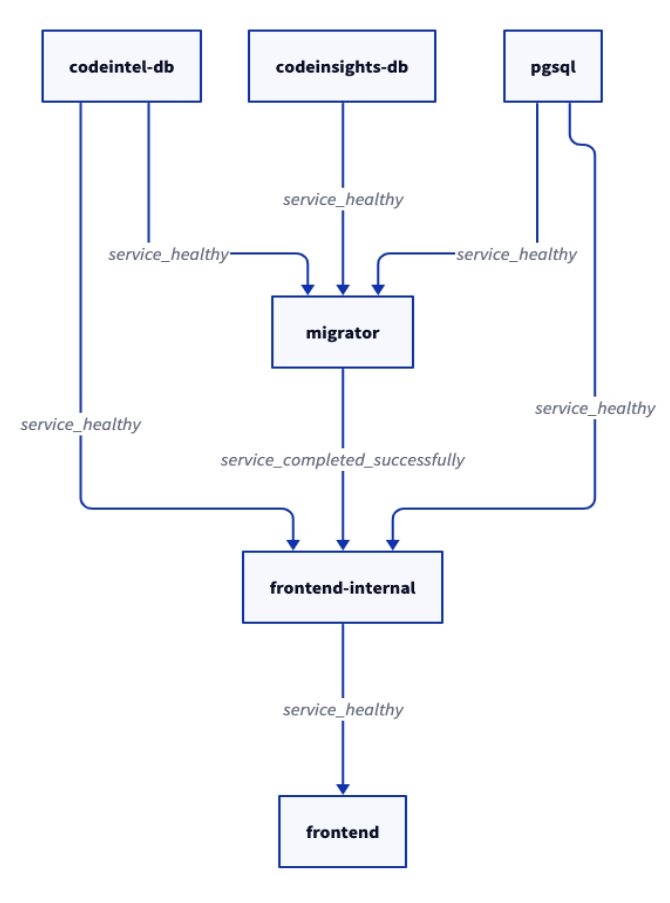
|
||||
|
||||
All of our deployment types currently utilize migrator during startup.
|
||||
The frontend service won't start until migrator has been run with the
|
||||
default up command. The frontend service will also validate the expected
|
||||
schema (and OOB migration progress), and die on startup if this
|
||||
validation pass fails. This ensures that the expected migrations for the
|
||||
version in question have been run.
|
||||
|
||||
In docker-compose (*see diagram)*, this is accomplished via a chain of
|
||||
`depends_on` clauses in the docker-compose.yaml
|
||||
([link](https://sourcegraph.com/github.com/sourcegraph/deploy-sourcegraph-docker/-/blob/docker-compose/docker-compose.yaml?L217-223)).
|
||||
|
||||
**For our k8s based deployments (including the AMIs) migrator is run as
|
||||
an initContainer within the frontend utilizing the up command on the
|
||||
given pods startup.**
|
||||
|
||||
- [Helm Ex](https://sourcegraph.com/github.com/sourcegraph/deploy-sourcegraph-helm/-/blob/charts/sourcegraph/templates/frontend/sourcegraph-frontend.Deployment.yaml?L49-76)
|
||||
- [Kustomize Ex](https://sourcegraph.com/github.com/sourcegraph/deploy-sourcegraph-k8s/-/blob/base/sourcegraph/frontend/sourcegraph-frontend.Deployment.yaml?L30-48)
|
||||
|
||||
|
||||
## Auto-upgrade
|
||||
|
||||
Migrator has been incrementally improved over the last year in an
|
||||
attempt to get closer and closer to auto-upgrades. After migrator v5.0.0
|
||||
logic was added to the `pgsql` database and `frontend`/`frontend-internal` service to
|
||||
attempt an automatic upgrade to the latest version of Sourcegraph on the startup of the frontend.
|
||||
|
||||
For more information about how this works see the
|
||||
[docs](https://docs.sourcegraph.com/admin/updates/automatic#automatic-multi-version-upgrades).
|
||||
Some notable points:
|
||||
|
||||
- The upgrade operations in this case are
|
||||
[triggered](https://sourcegraph.com/github.com/sourcegraph/sourcegraph@cf85b5803d32a91425f243930a4f50364625bcd2/-/blob/cmd/frontend/internal/cli/serve_cmd.go?L94-96)
|
||||
and
|
||||
[run](https://sourcegraph.com/github.com/sourcegraph/sourcegraph@cf85b5803d32a91425f243930a4f50364625bcd2/-/blob/cmd/frontend/internal/cli/autoupgrade.go?L37-145)
|
||||
by the frontend container.
|
||||
|
||||
- Migrator [looks
|
||||
for](https://sourcegraph.com/github.com/sourcegraph/sourcegraph@cf85b5803d32a91425f243930a4f50364625bcd2/-/blob/internal/database/migration/cliutil/up.go?L125-128)
|
||||
the existence of the env var SRC_AUTOUPGRADE=true on services
|
||||
`sourcegraph-frontend`, `sourcegraph-frontend-internal`, and `migrator`.
|
||||
Otherwise it [looks in the frontend
|
||||
db](https://sourcegraph.com/github.com/sourcegraph/sourcegraph@cf85b5803d32a91425f243930a4f50364625bcd2/-/blob/internal/database/migration/cliutil/up.go?L120-123)
|
||||
for the value of the autoupgrade column. These checks are performed
|
||||
with either the up or upgrade commands defined on the migrator.
|
||||
|
||||
- The internal connections package to the DB now uses a special
|
||||
[sentinel
|
||||
value](https://sourcegraph.com/github.com/sourcegraph/sourcegraph/-/blob/internal/database/dbconn/connect.go?L31-37)
|
||||
to make connection attempts sleep if migrations are in progress.
|
||||
|
||||
- A limited frontend is
|
||||
[served](https://sourcegraph.com/github.com/sourcegraph/sourcegraph@cf85b5803d32a91425f243930a4f50364625bcd2/-/blob/cmd/frontend/internal/cli/autoupgrade.go?L78-88)
|
||||
by the frontend during an autoupgrade, displaying progress of the
|
||||
upgrade and any drift encountered.
|
||||
|
||||
- All autoupgrades hit the multiversion upgrade endpoint and assume downtime for all Sourcegraph services besides the migrator and dbs.
|
||||
|
||||
## Migrator Release Artifacts
|
||||
|
||||
During the release of migrator we construct and build some artifacts
|
||||
used by migrator to support its operations. Different artifacts must be
|
||||
generated depending on the release type --
|
||||
|
||||
- **Major**
|
||||
|
||||
- [lastMinorVersionInMajorRelease](https://sourcegraph.com/github.com/sourcegraph/sourcegraph/-/blob/internal/oobmigration/version.go?L84-87):
|
||||
Used to evaluate what oobmigrations must run, must be updated
|
||||
every major release. This essentially tells us when a minor
|
||||
version becomes a major version. *It may be useful elsewhere at
|
||||
some point.*
|
||||
|
||||
- **Minor**
|
||||
|
||||
- [maxVersionString](https://sourcegraph.com/github.com/sourcegraph/sourcegraph@5851edf/-/blob/internal/database/migration/shared/data/cmd/generator/consts.go?L12I):
|
||||
Defined in `consts.go` this string is used to tell migrator the
|
||||
latest **minor** version targetable for MVU and oobmigrations.
|
||||
[If not
|
||||
updated](https://github.com/sourcegraph/sourcegraph/issues/55048)
|
||||
multiversion upgrades cannot target the latest release. *Note
|
||||
this is used to determine how many versions should be included
|
||||
in the `stitched-migration-graph.json` file.*
|
||||
|
||||
- [Stitched-migration.json](https://sourcegraph.com/github.com/sourcegraph/sourcegraph@v5.2.0/-/blob/internal/database/migration/shared/data/stitched-migration-graph.json):
|
||||
Used by multiversion upgrades to unsquash migrations. Generated
|
||||
during release
|
||||
[here](https://sourcegraph.com/github.com/sourcegraph/sourcegraph/-/blob/dev/release/src/release.ts?L1101-1110).
|
||||
Learn more below.
|
||||
|
||||
- **Patch**
|
||||
|
||||
- [Git_versions](https://sourcegraph.com/github.com/sourcegraph/sourcegraph/-/blob/cmd/migrator/generate.sh?L69-79):
|
||||
Defined in `generate.sh` this string array contains versions of
|
||||
Sourcegraph whose schemas should be embedded in migrator during a
|
||||
migrator build to enable drift detection without having to pull them
|
||||
directly from GitHub or, for older versions, from a pre-prepared GCS
|
||||
bucket (this is necessary in air gapped environments). This should
|
||||
be kept up to date with maxVersionString. [Learn
|
||||
more](https://github.com/sourcegraph/sourcegraph/issues/49813).
|
||||
|
||||
- [Squashed.sql](https://sourcegraph.com/github.com/sourcegraph/sourcegraph@v5.2.0/-/blob/migrations/frontend/squashed.sql):
|
||||
for each database we
|
||||
[generate](https://sourcegraph.com/github.com/sourcegraph/sourcegraph/-/blob/internal/database/gen.sh?L18-20)
|
||||
a new squashed.sql file. It is
|
||||
[used](https://sourcegraph.com/github.com/sourcegraph/sourcegraph@v5.2.0/-/blob/internal/database/migration/drift/util_search.go?L12-31)
|
||||
to help suggest fixes for certain types of database drift. For
|
||||
example for a missing database column [this
|
||||
search](https://sourcegraph.com/search?patternType=regexp&q=repo%3A%5Egithub%5C.com%2Fsourcegraph%2Fsourcegraph%24%40v5.0.6+file%3A%5Emigrations%2Ffrontend%2Fsquashed%5C.sql%24+%28%5E%7C%5Cb%29CREATE%5CsTABLE%5Csexternal_service_sync_jobs%28%24%7C%5Cb%29+OR+%28%5E%7C%5Cb%29ALTER%5CsTABLE%5CsONLY%5Csexternal_service_sync_jobs%28%24%7C%5Cb%29&groupBy=path)
|
||||
is used to suggest a definition.
|
||||
- [Schema
|
||||
descriptions](https://raw.githubusercontent.com/sourcegraph/sourcegraph/v5.2.0/internal/database/schema.json):
|
||||
schema descriptions are
|
||||
[embedded](https://sourcegraph.com/github.com/sourcegraph/sourcegraph@v5.2.0/-/blob/cmd/migrator/generate.sh?L64-66)
|
||||
in migrator on each new build as a reference for the expected schema
|
||||
state during drift checking.
|
||||
|
||||
### Stitched Migration JSON and Squashing Migrations
|
||||
|
||||
|
||||
|
||||
*\^\^ Generated with `sg migrations visualize --db frontend` on v5.2.0*
|
||||
|
||||
#### Squashing Migrations
|
||||
|
||||
[Periodically we
|
||||
squash](https://github.com/sourcegraph/sourcegraph/pull/41819)
|
||||
all migrations from two versions behind the current version into a
|
||||
single migration using sg migration squash. This reduces the time
|
||||
required to initialize a new database. This means that the migrator
|
||||
image is built with a set of definitions embedded that doesn't reflect
|
||||
the definition set in older versions. For multiversion upgrades this
|
||||
presents a problem. To get around this, on minor releases we generate a
|
||||
`stitched-migration-graph.json` file. Reference links:
|
||||
[Bazel](https://sourcegraph.com/github.com/sourcegraph/sourcegraph/-/blob/dev/release/src/util.ts?L293-327),
|
||||
[Embed](https://sourcegraph.com/github.com/sourcegraph/sourcegraph/-/blob/internal/database/migration/shared/embed.go?L15-22),
|
||||
[Generator](https://sourcegraph.com/github.com/sourcegraph/sourcegraph/-/blob/internal/database/migration/shared/data/cmd/generator/main.go)
|
||||
|
||||
#### Stitched Migration Graph
|
||||
|
||||
`stitched-migrations-graph.json` [stitches](https://sourcegraph.com/github.com/sourcegraph/sourcegraph@v5.2.0/-/blob/internal/database/migration/stitch/stitch.go) (you can think of this as unsquashing) historic migrations using git magic, enabling the migrator to have a reference of older migrations. This serves a few purposes:
|
||||
|
||||
1. When jumping across multiple versions we do not have access to a
|
||||
full record of migration definitions on migrator disk because some
|
||||
migrations will likely have been squashed. Therefore we need a way
|
||||
to ensure we don't miss migrations on a squash boundary. *Note we
|
||||
can't just re-apply the root migration after a squash because some
|
||||
schema state that\'s already represented in the root migration. This
|
||||
means the squashed root migration isn't always idempotent.*
|
||||
|
||||
2. During a multiversion upgrade migrator must schedule out of band
|
||||
migrations to be started at some version and completed before
|
||||
upgrading past some later version. Migrator needs access to the
|
||||
unsquashed migration definitions to know which migrations must have
|
||||
run at the time the oob migration is triggered.
|
||||
|
||||
In standard/`up` upgrades `stitched-migrations.json` isn't necessary. This
|
||||
is because `up` determines migrations to run by [comparing
|
||||
migrations](https://sourcegraph.com/github.com/sourcegraph/sourcegraph/-/blob/internal/database/migration/definition/definition.go?L214-244)
|
||||
listed as already run in the relevant db's `migration_logs` table directly
|
||||
to those migration definitions
|
||||
[embedded](https://sourcegraph.com/github.com/sourcegraph/sourcegraph/-/blob/migrations/embed.go)
|
||||
in the migrator disk at build time for the current version, and running
|
||||
any which haven't been run. We never squash away the previous minor
|
||||
version of Sourcegraph, in this way we can guarantee the `migration_logs`
|
||||
table migrations always has migrations in common with the migration
|
||||
definitions on disk.
|
||||
|
||||
### Database Drifts
|
||||
|
||||
Database drift is any difference between the expected state of the
|
||||
database at a given version and the actual state of the database. How
|
||||
does it come to be? We've observed drift in customer databases for a
|
||||
number of reasons, both due to admin tampering and problems in our own
|
||||
release process:
|
||||
|
||||
- **A backup/restore process that didn't include all objects**: This
|
||||
notably happened in a customer production instance causing their
|
||||
database to have no indexes, primary keys, or unique constraints defined.
|
||||
- **Modifying the database explicitly**: These are untracked manual
|
||||
changes to the database schema, observed occasionally in the wild,
|
||||
and in our dotcom deployment.
|
||||
- **Migration failures:** that occur during multi-version upgrade or
|
||||
the up command will cause the set of *successfully applied
|
||||
migrations* to be between two versions, where drift is well-defined.
|
||||
- **Site Admins Error:** Errors in git-ops like deploying to
|
||||
production on the wrong version of Sourcegraph manifests have
|
||||
introduced drift. Another source is the incorrect procedure in
|
||||
downgrading.
|
||||
- **Historic Bugs**: We, at one point, [too eagerly backfilled
|
||||
records that we should've instead
|
||||
applied](https://github.com/sourcegraph/sourcegraph/pull/55650).
|
||||
This bug was the result of changes being backported to the metadata
|
||||
definition of a migrations parent migrations, violating assumptions
|
||||
made during the generation of the stitched-migration-graph.json.
|
||||
|
||||
Database drift existing at the time of a migration can cause migrations
|
||||
to fail when they try to reference some table property that is not in
|
||||
the expected state. Not to mention the application may not behave as
|
||||
expected if drift is present. Migrator includes a `drift` command intended
|
||||
to help admins and CS team members to diagnose and resolve drift in
|
||||
customer instances. Multiversion upgrades in particular check for drift
|
||||
before starting unless the `--skip-drift-check argument` is supplied.
|
||||
|
||||
### Implementation Details
|
||||
|
||||
#### Versions & Runner
|
||||
|
||||
On startup the migrator service creates a
|
||||
[runner](https://sourcegraph.com/github.com/sourcegraph/sourcegraph@30d4d1dd457cde87c863a6d05cbcc0444025ed96/-/blob/cmd/migrator/shared/main.go?L31-36).
|
||||
|
||||
The `runner` is responsible for connecting to the given databases and
|
||||
[running](https://sourcegraph.com/github.com/sourcegraph/sourcegraph@4728edb797bc9affdbac940821c9e98c3fde2430/-/blob/internal/database/migration/runner/run.go)
|
||||
any schema migrations defined in the embedded `migrations` directory
|
||||
via the `up` entry command.
|
||||
|
||||
A `runner` [infers](https://sourcegraph.com/github.com/sourcegraph/sourcegraph@4728edb797bc9affdbac940821c9e98c3fde2430/-/blob/internal/database/migration/schemas/schemas.go) the expected state of the database from schema definitions
|
||||
[embeded in migrator](https://sourcegraph.com/github.com/sourcegraph/sourcegraph@30d4d1dd457cde87c863a6d05cbcc0444025ed96/-/blob/migrations/embed.go)
|
||||
when a migrator image is compiled. What this means is that migrator's concept of version,
|
||||
is the set of migrations defined in the `migrations` at compile time. In this way the `up` command easily facilitates dev versions of database schemas.
|
||||
|
||||
This "version" definition at compile time also tightly binds migrators concept of "version" to a given tag of Sourcegraph.
|
||||
**The `up` command will only initialize a version of Sourcegraph, when the `migrator`
|
||||
used to run `up` is the tagged version associated with the desired Sourcegraph version.**
|
||||
For this reason a later version of `migrator` cannot be used to initialize an earlier
|
||||
version of Sourcegraph.
|
||||
|
||||
For example, you use the latest migrator release `v5.6.9` to run the `upgrade` command bringing your databases from
|
||||
`v4.2.0` to `v5.6.3`, rather than `v5.6.9`. Your security team hasn't approved images past this point. The upgrade command will have applied OOB migrations and schema migrations defined up to `v5.6.0`, the last minor release. To start your image you'll need to run migrator
|
||||
`up` using the `v5.6.3` image, this will apply any schema migrations which may have been defined in the patch releases up to `v5.6.3` and thus existent in the embeded from `migrations` directory at the time of migrators compilation.
|
||||
|
||||
#### Migration Plan
|
||||
|
||||
While the `up` command's concept of version is a set of embedded definitions --
|
||||
the `upgrade` command does have a concept of schema migrations associated to
|
||||
version. This is the `stitched-migration-graph.json`. This file is generated on
|
||||
minor releases of Sourcegraph, and defines migrations expected to have been run
|
||||
at each minor version. This is necessary for two reasons --
|
||||
|
||||
1. The root migration defined in the `migration` directory is a squashed
|
||||
migration, meaning, it represents many migrations composed into a single
|
||||
sql statement.
|
||||
2. Out of Bound migrations are triggered at a given version, and must complete
|
||||
before the schema is changed in some subsequent version.
|
||||
|
||||
This means that when applying migrations defined accross multiple versions, migrator
|
||||
must stop and wait for OOB migrations to complete. To do this it needs to
|
||||
know which migrations should have run at a given stopping point, which may have been
|
||||
obscured by a subsequent squashing operation. This is where the `stitched-migration-graph.json`
|
||||
file comes into play. It defines the set of migrations that should have been run at
|
||||
a given minor version. Helping to construct a "[migration plan](https://sourcegraph.com/github.com/sourcegraph/sourcegraph@4728edb797bc9affdbac940821c9e98c3fde2430/-/blob/internal/database/migration/multiversion/plan.go)" or path for `runner` to traverse.
|
||||
|
||||
The `stitched-migration.json` file is [generated](https://sourcegraph.com/github.com/sourcegraph/sourcegraph@4728edb797bc9affdbac940821c9e98c3fde2430/-/blob/internal/database/migration/stitch/stitch.go) on every minor release, and is informed
|
||||
by the state of the acyclic graph of migrations defined in the `migration` directory.
|
||||
@ -1,4 +1,4 @@
|
||||
# Permissions
|
||||
# RBAC Permissions
|
||||
|
||||
This doc is for engineers who want to add permissions for features they want to protect using the Access Control System. The permission referred to in this context differs from repository permissions; the latter concerns permissions from code hosts relating to repositories.
|
||||
|
||||
@ -22,10 +22,10 @@ To add permissions for a new feature, follow these steps:
|
||||
|
||||
1. Add the namespace and action to [`schema.yaml`](https://sourcegraph.sourcegraph.com/github.com/sourcegraph/sourcegraph/-/blob/internal/rbac/schema.yaml). Namespace string must be unique.
|
||||
|
||||
2. Generate the access control constants with the command `sg gen`. This will generate access control constants for [Typescript](https://sourcegraph.sourcegraph.com/github.com/sourcegraph/sourcegraph@8b4e1cb/-/blob/client/web/src/rbac/constants.ts) and [Go](https://sourcegraph.sourcegraph.com/github.com/sourcegraph/sourcegraph@8b4e1cb4374d1449c918f695c21d2c933c5a1d15/-/blob/internal/rbac/constants.go).
|
||||
2. Generate the access control constants with the command `bazel run //dev:write_all_generated`. This will generate access control constants for [Typescript](https://sourcegraph.sourcegraph.com/github.com/sourcegraph/sourcegraph@8b4e1cb/-/blob/client/web/src/rbac/constants.ts) and [Go](https://sourcegraph.sourcegraph.com/github.com/sourcegraph/sourcegraph@8b4e1cb4374d1449c918f695c21d2c933c5a1d15/-/blob/internal/rbac/constants.go).
|
||||
- Additionally modify [schema.graphql](https://sourcegraph.sourcegraph.com/github.com/sourcegraph/sourcegraph@2badaeb3ccb0d9bf660234e8b5eddb4cba6598bb/-/blob/cmd/frontend/graphqlbackend/schema.graphql?L9729) by adding a new namespace enum
|
||||
|
||||
3. Once these constants have been generated, you can protect any resource using the access control system.
|
||||
3. Once these constants have been generated, you can protect any resource using the access control system.
|
||||
* In Go, you can do this by importing the [`CheckCurrentUserHasPermission`](https://sourcegraph.sourcegraph.com/github.com/sourcegraph/sourcegraph@8b4e1cb/-/blob/internal/rbac/permission.go) method from the `internal/rbac` package. [Example](https://github.com/sourcegraph/sourcegraph/pull/49594/files).
|
||||
|
||||
* In Typescript, you can do this by accessing the authenticated user's permissions and verifying the [permission](https://sourcegraph.sourcegraph.com/github.com/sourcegraph/sourcegraph@8b4e1cb4374d1449c918f695c21d2c933c5a1d15/-/blob/client/web/src/rbac/constants.ts?L5:14-5:41) you require is contained in the array. [Example](https://sourcegraph.sourcegraph.com/github.com/sourcegraph/sourcegraph@8b4e1cb4374d1449c918f695c21d2c933c5a1d15/-/blob/client/web/src/batches/utils.ts?L6)
|
||||
|
||||
@ -1,6 +1,6 @@
|
||||
# How to set up Cody Gateway locally
|
||||
|
||||
> WARNING: This is a development guide - to use Cody Gateway for Sourcegraph, refer to [Sourcegraph Cody Gateway](../../cody/core-concepts/cody-gateway.md).
|
||||
> WARNING: This is a development guide - to use Cody Gateway for Sourcegraph, refer to [Sourcegraph Cody Gateway](https://sourcegraph.com/docs/cody/core-concepts/cody-gateway).
|
||||
|
||||
This guide documents how to set up [Cody Gateway](https://handbook.sourcegraph.com/departments/engineering/teams/cody/cody-gateway/) locally for development.
|
||||
|
||||
@ -16,13 +16,7 @@ To use the locally running Cody Gateway, follow the steps in [use a locally runn
|
||||
|
||||
## Use a locally running Cody Gateway
|
||||
|
||||
First, set up some feature flags on your local Sourcegraph instance:
|
||||
|
||||
- `product-subscriptions-service-account`: set to `true` globally for convenience.
|
||||
In production, this flag is used to denote service accounts, but in development it doesn't matter.
|
||||
- You can also create an additional user and set this flag to `true` only for that user for more robust testing.
|
||||
|
||||
To use this locally running Cody Gateway from your local Sourcegraph instance, configure Cody features to talk to your local Cody Gateway in site configuration, similar to what [customers do to enable Cody Enterprise](../../cody/overview/enable-cody-enterprise.md):
|
||||
To use this locally running Cody Gateway from your local Sourcegraph instance, configure Cody features to talk to your local Cody Gateway in site configuration, similar to what [customers do to enable Cody Enterprise](https://sourcegraph.com/docs/cody/overview/enable-cody-enterprise):
|
||||
|
||||
```json
|
||||
{
|
||||
@ -32,7 +26,7 @@ To use this locally running Cody Gateway from your local Sourcegraph instance, c
|
||||
"endpoint": "http://localhost:9992",
|
||||
"chatModel": "anthropic/claude-2",
|
||||
"completionModel": "anthropic/claude-instant-1",
|
||||
// Create a subscription and create a license key:
|
||||
// Create an Enterprise subscription and license key:
|
||||
// https://sourcegraph.test:3443/site-admin/dotcom/product/subscriptions
|
||||
// Under "Cody services", ensure access is enabled and get the access token
|
||||
// to use here.
|
||||
@ -42,7 +36,7 @@ To use this locally running Cody Gateway from your local Sourcegraph instance, c
|
||||
}
|
||||
```
|
||||
|
||||
Similar values can be [configured for embeddings](https://docs.sourcegraph.com/cody/core-concepts/embeddings) to use embeddings through your local Cody Gateway isntead.
|
||||
Similar values can be [configured for embeddings](https://sourcegraph.com/docs/cody/core-concepts/embeddings) to use embeddings through your local Cody Gateway isntead.
|
||||
|
||||
Now, we need to make sure your local Cody Gateway instance can access upstream LLM services.
|
||||
Add the following to your `sg.config.overwrite.yaml`:
|
||||
@ -55,8 +49,8 @@ commands:
|
||||
# https://start.1password.com/open/i?a=HEDEDSLHPBFGRBTKAKJWE23XX4&h=my.1password.com&i=athw572l6xqqvtnbbgadevgbqi&v=dnrhbauihkhjs5ag6vszsme45a
|
||||
CODY_GATEWAY_ANTHROPIC_ACCESS_TOKEN: "..."
|
||||
# Create a personal access token on https://sourcegraph.test:3443/user/settings/tokens
|
||||
# or on your `product-subscriptions-service-account` user. This allows your
|
||||
# local Cody Gateway to access user information in the Sourcegraph instance.
|
||||
# for your local site admin user. This allows your local Cody Gateway to
|
||||
# access user information in the Sourcegraph instance.
|
||||
CODY_GATEWAY_DOTCOM_ACCESS_TOKEN: "..."
|
||||
# Other values, such as CODY_GATEWAY_OPENAI_ACCESS_TOKEN and
|
||||
# CODY_GATEWAY_OPENAI_ORG_ID, can be set to access OpenAI services as well.
|
||||
@ -87,7 +81,7 @@ commands:
|
||||
CODY_GATEWAY_BIGQUERY_PROJECT_ID: cody-gateway-dev
|
||||
```
|
||||
|
||||
Then to view events statistics on the product subscription page, add the following section in the site configuration, and run the `sg start dotcom` stack:
|
||||
Then to view events statistics on the Enterprise subscriptions page, add the following section in the site configuration, and run the `sg start dotcom` stack:
|
||||
|
||||
```json
|
||||
{
|
||||
|
||||
68
doc/dev/how-to/debug_permissions.md
Normal file
68
doc/dev/how-to/debug_permissions.md
Normal file
@ -0,0 +1,68 @@
|
||||
# Debugging Repository Permissions
|
||||
|
||||
This document provides a list of options to try when debugging permissions issues.
|
||||
|
||||
## Check the user permissions screen
|
||||
|
||||
1. As a site administrator, visit the **Site admin** > **User administration** page and search for the user in question.
|
||||
|
||||
2. Click on their username and navigate to their **Settings** > **Permissions** page.
|
||||
This page gives an overview of a user's permission sync jobs, as well as the repositories they have access to and why.
|
||||
|
||||
3. At the bottom of the **Permissions** page, you'll find a list of repositories the user can access and the reason for their access. Possible access reasons are:
|
||||
- **Public** - The repository is marked as public on the code host, so all users on the Sourcegraph instance can access this repository.
|
||||
- **Unrestricted** - The code host connection that this repository belongs to is not enforcing authorization, so all users on the Sourcegraph instance can access this repository.
|
||||
- **Permissions Sync** - The user has access to this repository because they have connected an external account with access to it on the code host.
|
||||
- **Explicit API** - The user has been granted explicit access to this repository using the explicit permissions API.
|
||||
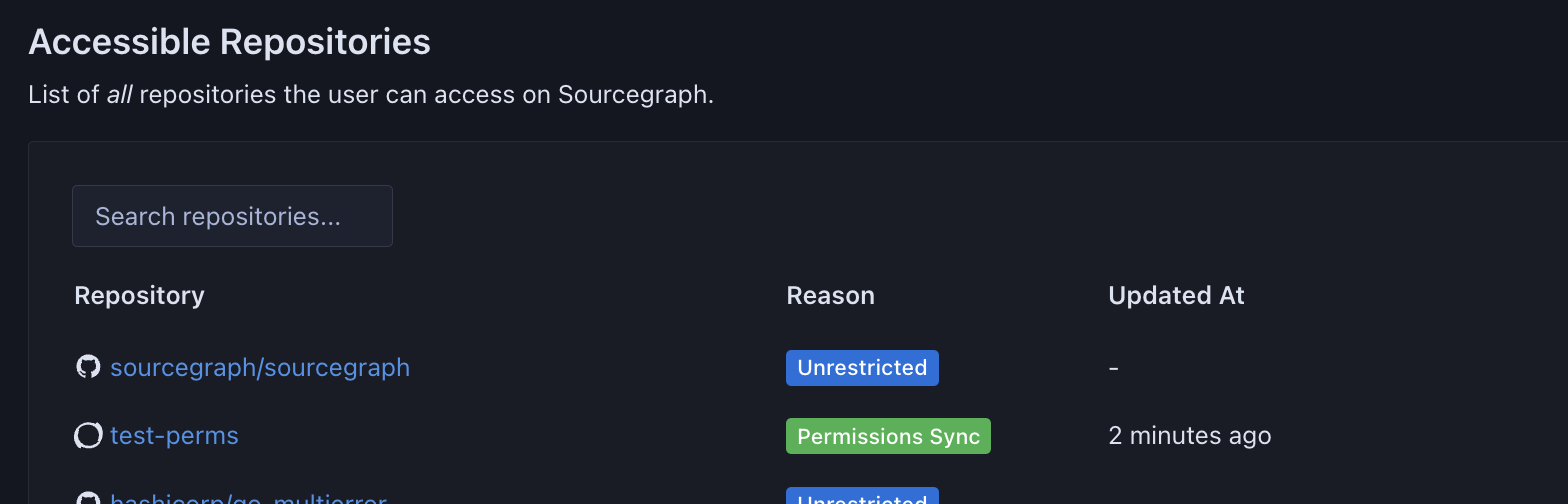
|
||||
4. If the user should have access to a repository, but the repository is not at all present in this list, check if the user has connected their code host account to their user profile.
|
||||
|
||||
## Check the user's Account security page
|
||||
|
||||
1. As a site administrator, navigate to the user's settings and select **Account security**.
|
||||
|
||||
- This page shows a user's connected external accounts. An external account is required to sync user permissions from code hosts.
|
||||
2. If a user has not connected their code host account, the user will have to do that by visiting their Account security settings and clicking on Add. Without a connected code host account, Sourcegraph is not able to associate their Sourcegraph identity with a code host identity to map permissions. If you don’t see the provider for your code host here, you have to [configure it first](https://sourcegraph.com/docs/admin/auth).
|
||||
3. If the account is connected, you can revisit the Permissions page, schedule another permissions sync, and see if anything changes. If nothing changes when a permission sync is complete, check the outbound requests log to verify that code host API calls are succeeding.
|
||||
|
||||
## Check the outbound requests log
|
||||
|
||||
1. On the Site admin settings page, click on the Outbound requests option near the bottom.
|
||||
|
||||
2. If outbound requests aren’t enabled, you’ll need to enable it first. In the site configuration, add `"outboundRequestLogLimit": 50`, (50 indicates the number of most recent requests to store. Adjust as needed).
|
||||
3. The Outbound requests page will show a list of all the HTTP requests Sourcegraph is making to outside services. Calls made to do user/repo permissions syncs will also show up here. You can try to catch a user permission sync "in the act" by scheduling a sync and visiting the Outbound requests page.
|
||||
|
||||
4. Here, we can see a bunch of API calls being made to the GitLab API, and they seem to be succeeding. To stop the list from refreshing every 5 seconds, you can click on the Pause updating button, and to see more details, you can click on the More info option.
|
||||
- You'll need to use your judgment to determine if anything looks out of place. Ideally, you'd like to see calls to the code host. You want to see those calls succeed with a 200 OK status code. Look at the URLs to see if they make sense. Does anything seem weird?
|
||||
|
||||
## Configure authorization for a code host connection
|
||||
|
||||
1. Select the Code host connections section on the Site admin settings page. You should see a list of code host connections.
|
||||
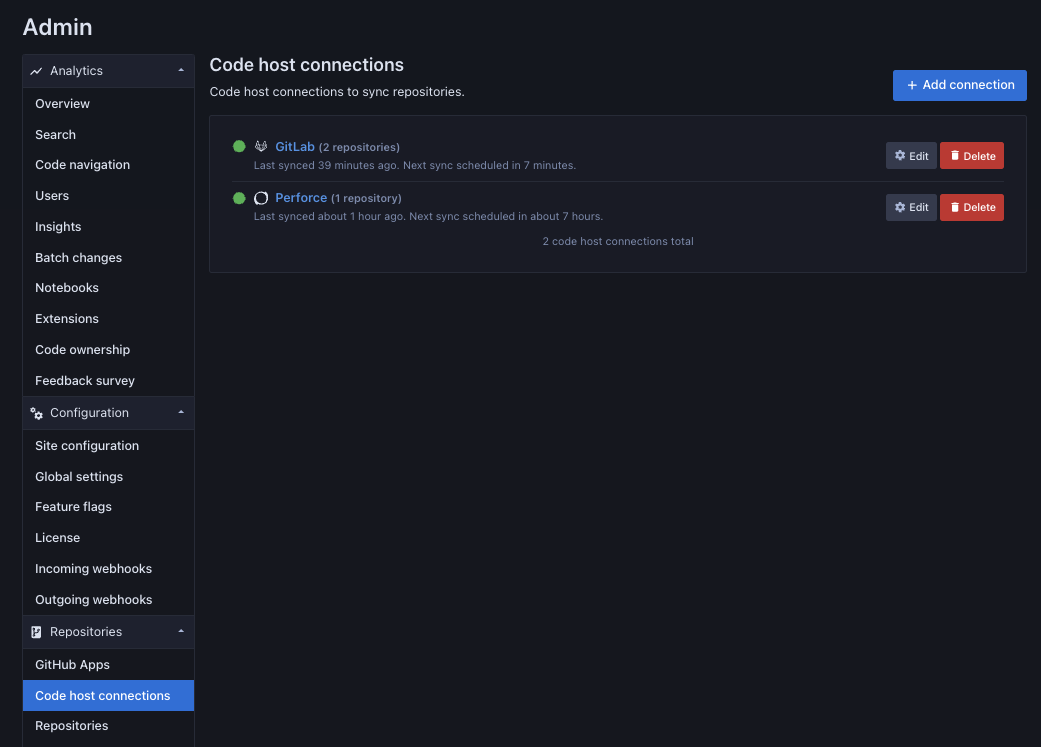
|
||||
2. Select the code host that you’d like to view, which should show you its configuration page.
|
||||
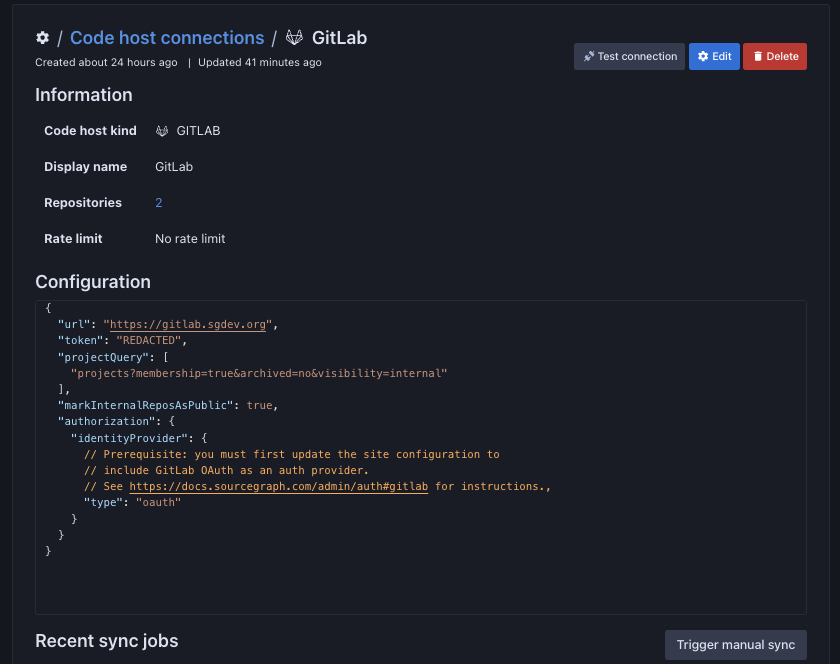
|
||||
- Here you can see that this GitLab connection is configured with authorization. If the authorization field is missing completely then the code host connection will be marked as “unrestricted” and all repositories synced by that code host connection will be accessible to everyone on Sourcegraph.
|
||||
- Not all authorization configurations are the same. Visit the [code hosts docs page](https://sourcegraph.com/docs/admin/external_service#configure-a-code-host-connection) for more detailed information on configuring authorization for the specific code host you’re dealing with.
|
||||
3. Once you’ve adjusted and saved the config, a sync should be triggered for the code host. If no sync was triggered, hit the Trigger manual sync button.
|
||||
4. Next, check the user permissions screen to see if things are behaving as expected now, and if nothing has changed, try scheduling a permissions sync.
|
||||
|
||||
## Is the repo public on the code host but not public on Sourcegraph or vice versa?
|
||||
|
||||
1. Confirm that the repository on the code host has the visibility you expect it to have.
|
||||
- Does the code host even have a concept of visibility? Some enterprise code hosts don’t have a concept of “publically available” repositories.
|
||||
2. Confirm that the visibility of the repository on Sourcegraph differs from what you saw on the code host itself.
|
||||
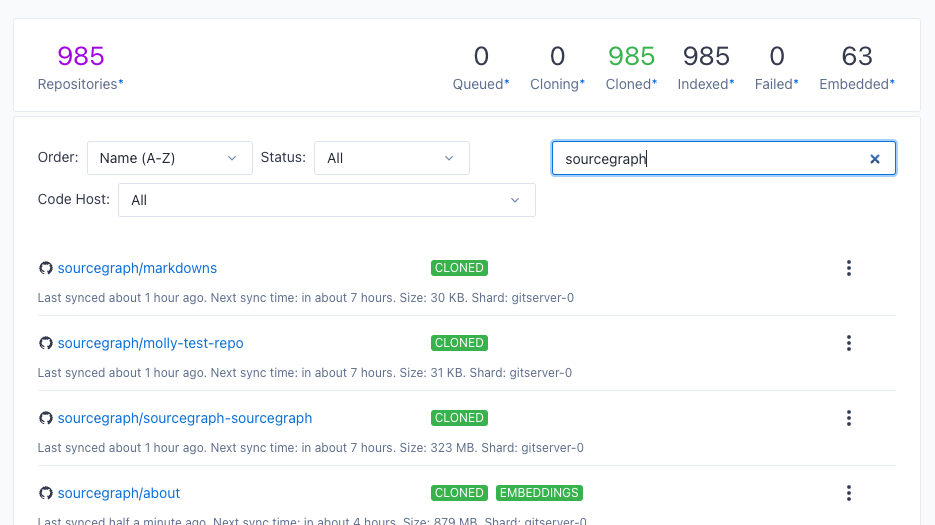
|
||||
- Private repositories on Sourcegraph will have the Private label as displayed above. If that label is not there, consider the repo to be public.
|
||||
3. If there is a discrepancy between the visibility of the repository on the code host vs. Sourcegraph, it could point to a bug on Sourcegraph’s side.
|
||||
|
||||
## Is the repository actually present on Sourcegraph?
|
||||
|
||||
1. Navigate to the **Site admin** settings and select **Repositories** under the **Repositories** section in the navigation menu.
|
||||
|
||||
2. Search for the repository in question.
|
||||

|
||||
3. If the repository does not show up, but you expect it to, the instance may be configured to enforce repository permissions even for site admins. In this case, the site admin can only see the repository if they have explicit access. It may be worth temporarily turning off this enforcement for debugging purposes.
|
||||
4. To disable permissions enforcement for site administrators, navigate to the Site Configuration section.
|
||||
|
||||
5. In the site configuration, there will be a line that reads `"authz.enforceForSiteAdmins": true` . Set it to false. Attempt to search for the repository again.
|
||||
- If there is no such entry, or if the setting is already set to false, the repository is not synced to Sourcegraph at all, and the fault is most likely in the code host connection.
|
||||
@ -62,6 +62,10 @@
|
||||
|
||||
- [Adding permissions](add_permissions.md)
|
||||
|
||||
## Repository Permissions
|
||||
|
||||
- [Debugging Repository permissions](debug_permissions.md)
|
||||
|
||||
## Wolfi
|
||||
|
||||
- [How to add and update Wolfi packages](wolfi/add_update_packages.md)
|
||||
|
||||
@ -109,7 +109,7 @@ Clarification and discussion about key concepts, architecture, and development s
|
||||
- [Testing web code](background-information/testing_web_code.md)
|
||||
- [Building p4-fusion](background-information/build_p4_fusion.md)
|
||||
- [The `gitserver` API](background-information/gitserver-api.md)
|
||||
- [Using gRPC alongside REST for internal APIs](background-information/gRPC_internal_api.md)
|
||||
- [gRPC Tutorial](background-information/grpc_tutorial.md)
|
||||
|
||||
### Git
|
||||
|
||||
|
||||
@ -2,17 +2,30 @@
|
||||
|
||||
Sourcegraph uses a number of secret formats to store authentication tokens and keys. This page documents each secret type, and the regular expressions that can be used to match each format.
|
||||
|
||||
| Token Name | Description | Type | Regular Expression |
|
||||
| -------------------------------------------- | -------------------------------------------------------------------------------- | -------------------------- | ------------------------------------------------- |
|
||||
| Sourcegraph Access Token (v3) | Token used to access the Sourcegraph GraphQL API | User-generated | `sgp_(?:[a-fA-F0-9]{16} \|local)_[a-fA-F0-9]{40}` |
|
||||
| Sourcegraph Access Token (v2, deprecated) | Token used to access the Sourcegraph GraphQL API | User-generated | `sgp_[a-fA-F0-9]{40}` |
|
||||
| Sourcegraph Access Token (v1, deprecated) | Token used to access the Sourcegraph GraphQL API | User-generated | `[a-fA-F0-9]{40}` |
|
||||
| Sourcegraph Dotcom User Gateway Access Token | Token used to grant sourcegraph.com users access to Cody | Backend (not user-visible) | `sgd_[a-fA-F0-9]{64}` |
|
||||
| Sourcegraph License Key Token | Token used for product subscriptions, derived from a Sourcegraph license key | Backend (not user-visible) | `slk_[a-fA-F0-9]{64}` |
|
||||
| Sourcegraph Product Subscription Token | Token used for product subscriptions, not derived from a Sourcegraph license key | Backend (not user-visible) | `sgs_[a-fA-F0-9]{64}` |
|
||||
| Token Name | Description | Type | Regular Expression | |
|
||||
| -------------------------------------------- | -------------------------------------------------------------------------------- | -------------------------- | ------------------------- | ----------------------- |
|
||||
| Sourcegraph Access Token (v3) | Token used to access the Sourcegraph GraphQL API | User-generated | `sgp_(?:[a-fA-F0-9]{16} \ | local)_[a-fA-F0-9]{40}` |
|
||||
| Sourcegraph Access Token (v2, deprecated) | Token used to access the Sourcegraph GraphQL API | User-generated | `sgp_[a-fA-F0-9]{40}` | |
|
||||
| Sourcegraph Access Token (v1, deprecated) | Token used to access the Sourcegraph GraphQL API | User-generated | `[a-fA-F0-9]{40}` | |
|
||||
| Sourcegraph Dotcom User Gateway Access Token | Token used to grant sourcegraph.com users access to Cody | Backend (not user-visible) | `sgd_[a-fA-F0-9]{64}` | |
|
||||
| Sourcegraph License Key Token | Token used for product subscriptions, derived from a Sourcegraph license key | Backend (not user-visible) | `slk_[a-fA-F0-9]{64}` | |
|
||||
| Sourcegraph Enterprise subscription (aka "product subscription") Token | Token used for Enterprise subscriptions, derived from a Sourcegraph license key | Backend (not user-visible) | `sgs_[a-fA-F0-9]{64}` | |
|
||||
|
||||
For further information about Sourcegraph Access Tokens, see:
|
||||
- [Creating an access token](../../cli/how-tos/creating_an_access_token.md)
|
||||
- [Revoking an access token](../../cli/how-tos/revoking_an_access_token.md)
|
||||
- [Creating an access token](https://sourcegraph.com/docs/cli/how-tos/creating_an_access_token)
|
||||
- [Revoking an access token](https://sourcegraph.com/docs/cli/how-tos/revoking_an_access_token)
|
||||
|
||||
Sourcegraph is in the process of rolling out a new Sourcegraph Access Token format. When generating an access token you may receive a token in v2 or v3 format depending on your Sourcegraph instance's version. Newer instances are fully backwards-compatible with all older formats.
|
||||
|
||||
|
||||
### Sourcegraph Access Token (v3) Instance Identifier
|
||||
The Sourcegraph Access Token (v3) includes an *instance identifier* which can be used by Sourcegraph to securely identify which instance the token was generated for. In the event of a token leak, this allows us to inform the relevant customer.
|
||||
|
||||
```
|
||||
sgp _ <instance identifier> _ <token value>
|
||||
```
|
||||
|
||||
The *instance identifier* is intentionally **not** verified when a token is used, so tokens will remain valid if it is modified. This doesn't impact the security of our access tokens. For example, the following tokens have the same *token value* so are equivalent:
|
||||
|
||||
* `sgp_foobar_abcdef0123456789`
|
||||
* `sgp_bazbar_abcdef0123456789`
|
||||
|
||||
@ -4,7 +4,7 @@ This is the quickstart guide for [developing Sourcegraph](../index.md).
|
||||
|
||||
> NOTE: If you run into any troubles, reach out on Slack:
|
||||
>
|
||||
> - [As an open source contributor](https://sourcegraph-community.slack.com/archives/C02BG0M0ZJ7)
|
||||
> - [As an open source contributor](https://discord.com/servers/sourcegraph-969688426372825169)
|
||||
> - [As a Sourcegraph employee](https://sourcegraph.slack.com/archives/C01N83PS4TU)
|
||||
>
|
||||
> You can also get help on our [developer experience discussion forum](https://github.com/sourcegraph/sourcegraph/discussions/categories/developer-experience).
|
||||
|
||||
Loading…
Reference in New Issue
Block a user